Meditating with microprocessors
- Artificial Intelligence based Hardware(Microprocessor) tuning: Implementing a very simple idea (part-1)
- A crashcourse in Microarchitecture and Linux CPUIDLE interface (part-2)
- Trading off power for UltraLowLatency (part-3)
- Artificial Intelligence guided Predictive MicroProcessor tuning (part-4)
- Introduction
- Is there a solution?
- Is there a smarter solution?: Artificial Intelligence model based proactive decision making
- Recognizing the pattern
- Transformer as the backbone
- Transfer Learning inspiration from NLP
- Fine tuning pre-trained networks
- Artificial Intelligence model based proactive and predictive decision making
- The Final Cut
- Summary
- Appendix:Tools of the trade (part-5)
Introduction
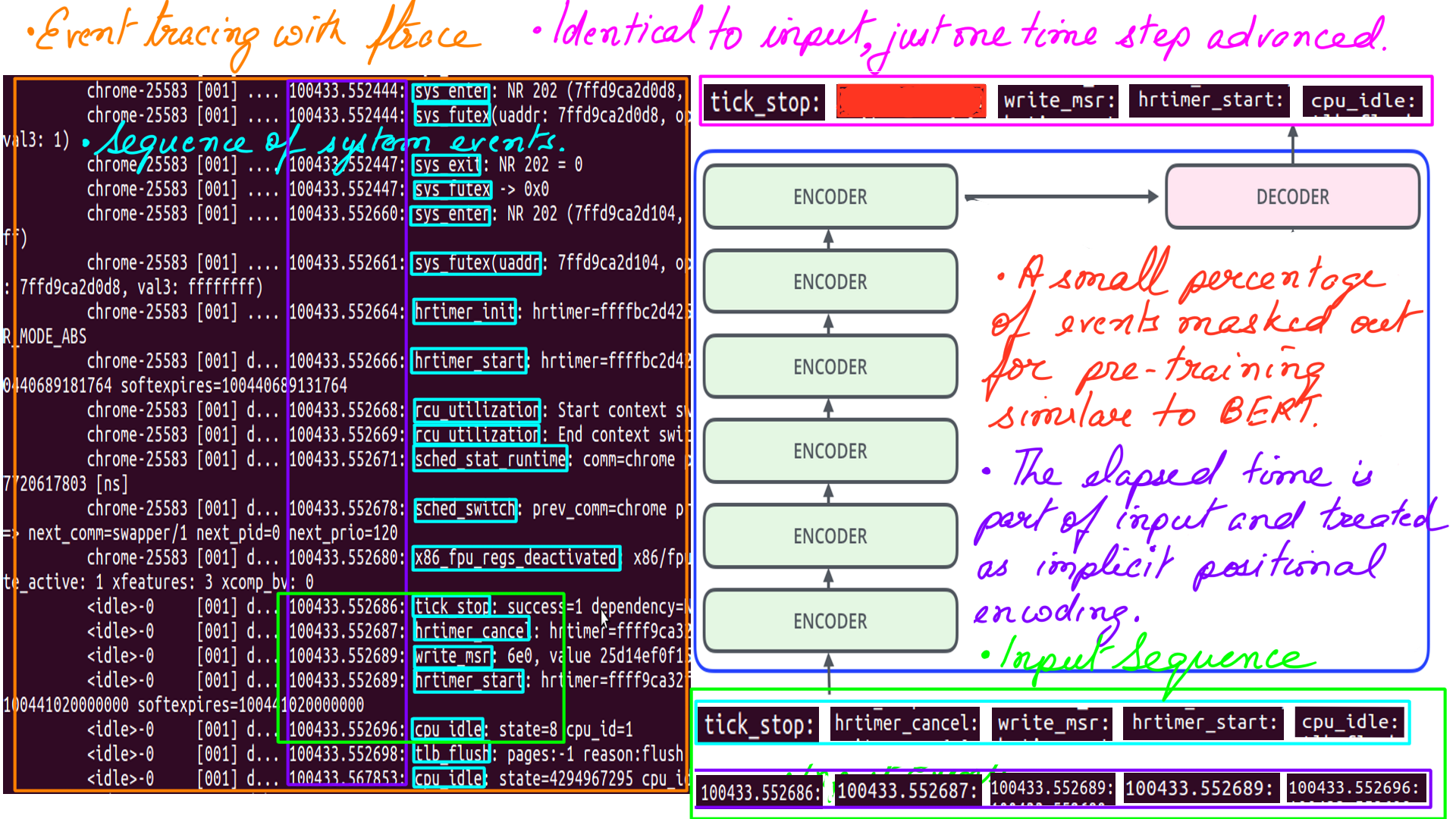
The current article is part of a bigger series titled Meditating-with-microprocessors, in which I demonstrate the use of Artificial Intelligence to tune microprocessors for Ultra Low Latency and Realtime loads. There are 5 parts to the series, Meditating with Microprocessors: An essentially simple idea(part-1) , A crashcourse in Microarchitecture and Linux CPUIDLE interface(part-2), Core (part-3) , Uncore (part-4), Appendix:Tools (part-5). In the current article, we explore the use of Artificial Intelligence to reduce latency and save power at the same time. As we have understood, left to itself, the microprocessor will sense the load and configure itself for it(suitable c-states, P-states, etc. ). However, this process is reactive at best, and if latency matters then it is already late. By reactive, I mean the arrival of a remote message triggers an interrupt and from there, one thing leads to another before the microprocessor configures itself for the load. Causal is another word for it. Let me put this in perspective. On a modern microprocessor with an average clock speed of roughly 2.5 gigahertz, there are 2500000000 cycles executed per second or 2.5 cycles per nanoseconds. A single instruction can take anywhere between a single cycle to a few tens of cycles depending upon the complexity of the instruction. At this granularity, the moment the CPU can spare a few hundred to a few thousands of nanoseconds of no work, it looks for an opportunity to get into a deep c-state or a low p-state. This is all guided by the policy of the system enforced by the OS. As a result, there are far too many transitions in a short time, costing valuable time in terms of latency and inducing jitter. We are not even talking about a millisecond granularity. Here is an example of roughly 25000 transitions in a period of 15 seconds. With an Artificial Intelligence based model can we reduce latency by predicting load and preconfigure the microprocessor for load and then postconfigure it to save power once the load has tided over. In other words making the process more proactive and predictive.
Is there a solution?
Well, one solution can be the other extreme. Configure the CPU such that it can never transition out to deeper c-states or lower p-states. This is what I did in the earlier articles. However, this causes a power drain, especially if done for a long time. The other issue is crossing the Thermal Design Point(TDP). A TDP condition identifies this (power, frequency) pair. This is the limit, operating under which the CPU will never exceed its thermal envelope. TDP marks the worst-case real workload that a customer may run without causing thermal throttling. However, TDP is not a standard that every manufacturer agrees on and is often underestimated. This results in applications causing the CPU to exceed its TDP oftentimes. On average, everything still works fine but occasionally things may go wrong(I burnt one of my laptops(Not the CPU) 9-10 years ago testing things out). Lastly, long term wear and tear may be an issue if the CPU deepest state is C0 and the CPU is overclocked for a long time or permanently. That being said, most modern devices are fairly tolerant of overclocking.
Is there a smarter solution?: Artificial Intelligence model based proactive decision making
The idea is quite simple. Use Artificial Intelligence to predict an oncoming load, and change the microprocessor settings to high performance to suit the load. Isolate the high-performance settings on a fraction of cores depending on the requirement and not the complete system. Reset it back to normal once the load has passed over. If an Artificial Intelligence model can recognize a pattern of load much before it occurs then we have a winner here. And we can then call it proactive instead of reactive or causal.
Recognizing the pattern
This part is a bit proprietary so the details will be sketchy but the ideas will be clear. Just like a signature or fingerprint is unique to a person, is there a unique signature to a load. And if a particular load has a unique signature, is there a way to identify it? Last but not least, the identification process must be the least interfering. Remember, the idea is to reduce latency. If the whole process of identification of load has a huge observer effect, then it may not be worth the effort. As it turns out, there are ways to capture the pattern of load in a non-intrusive way. And I take solid inspiration from NLP for that.
Transformer as the backbone
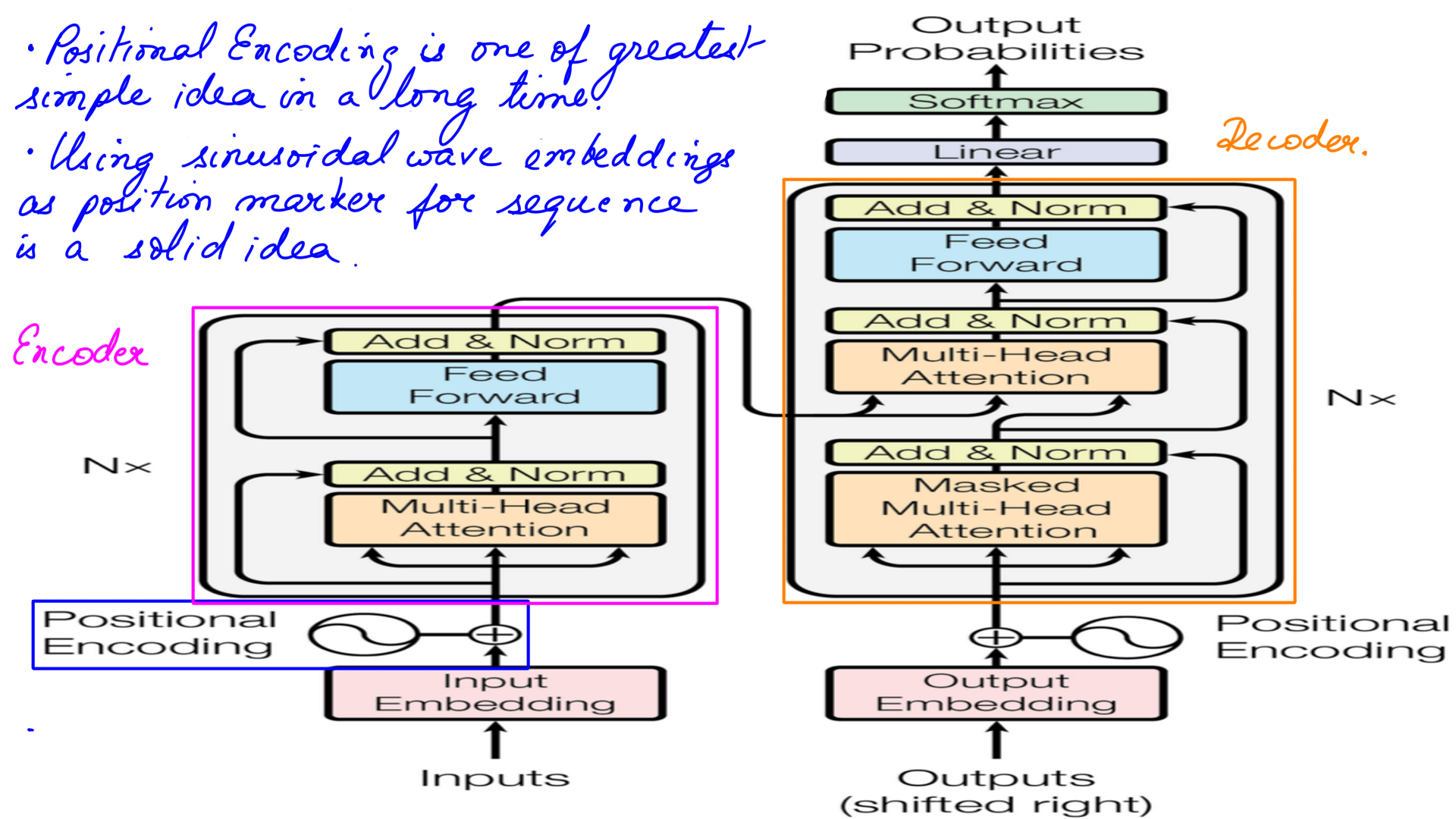
NeuralMachineTranslators (NMT) based on LSTM had excellent results but had few major challenges. Foremost was the inability to feed data parallelly that impacted not just the speed of training these models but also the amount of data fed in. Transformer’s architecture in many ways changed the course of NLP with a lot of improvements over the previous generation NMT architectures that were based on LSTMs. While Transformers retained the core encoder-decoder setup there were some vital changes.
- First improvement was positional encoding. Allowing sequential data to be fed in parallelly and yet retain positional information is one of the greatest simple ideas in AI in along time.
- Using sinusoidal wave embeddings as position markers is a solid idea. This allowed data to be fed in parallelly, but even more crucially a bidirectional context could be built without physically feeding the data in both directions.
- In terms of training speed alone this was light years faster especially with GPUs.With much faster training speeds, there are other positive side effects like a much bigger corpus of data could be trained with.
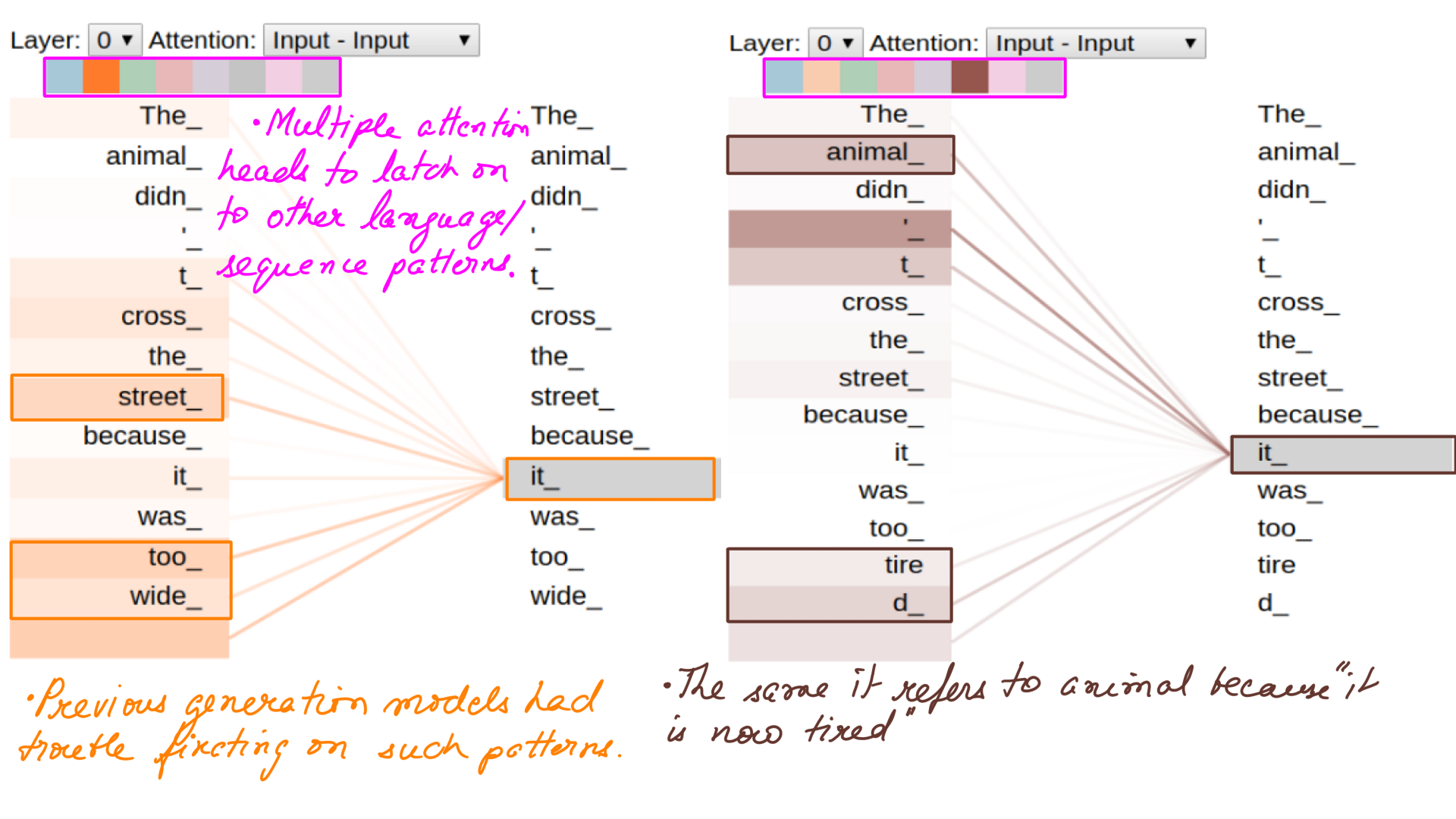
- Second big change was Multi-Headed-Attention. Attention by itself has been in the industry for quite some time. However with Multi-Headed-Attention, the model can fixate on multiple patterns within a sequence. And the number of patterns depends on the configurable number of AttentionHeads
Transfer Learning inspiration from NLP
I have taken a lot of inspiration from the use of Transfer Learning in Artificial Intelligence and especially in Natural Language Processing.
Here are the key ideas.
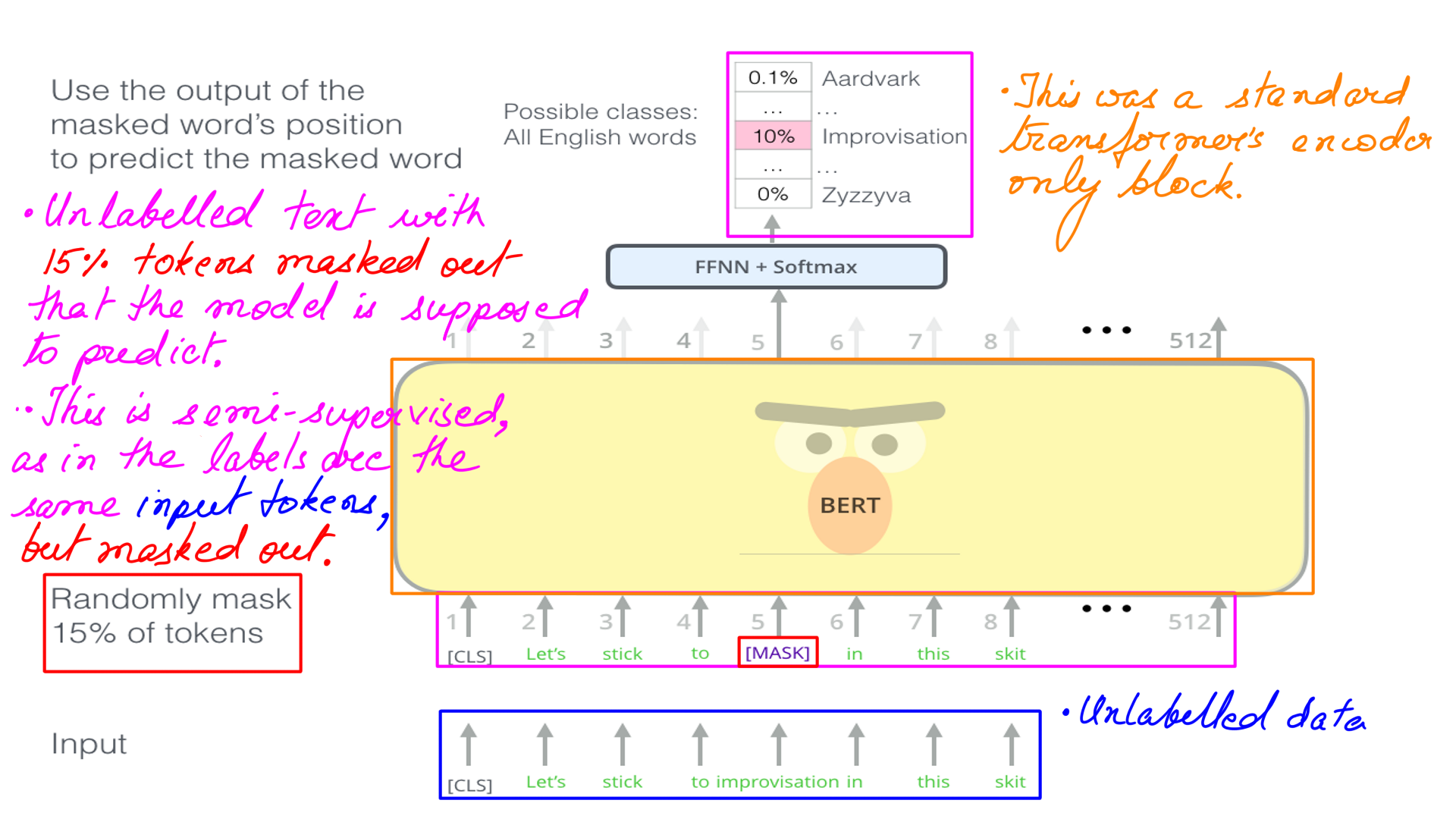
- Annotated and labeled data are difficult to find but unlabelled data is plentiful. Wikipedia, Online books are just some examples.
- Transfer Learning exemplifies learning with unlabelled data.
- The NLP breakthroughs of 2018 and 2019 were triggered in a big way by Transfer Learning’s application on Transformers.
- BERT was a breakthrough performer in NLP when it had come out in 2018.
- The idea of masking was a breath of fresh air, inspiring other techniques like SpecAugment used in speech processing.
- One of the ideas behind Random masking is that the context(self-attention calculations) can be bidirectional. This is one of the major reasons for BERT to outperform GPT which uses causal masking.
- The recent success of transfer learning was ignited in 2018 by GPT, ULMFiT, ELMo, and BERT, and 2019 saw the development of a huge diversity of new methods like XLNet, RoBERTa, ALBERT, Reformer, and MT-DNN.
- The rate of progress in the field has made it difficult to evaluate which improvements are most meaningful and how effective they are when combined.
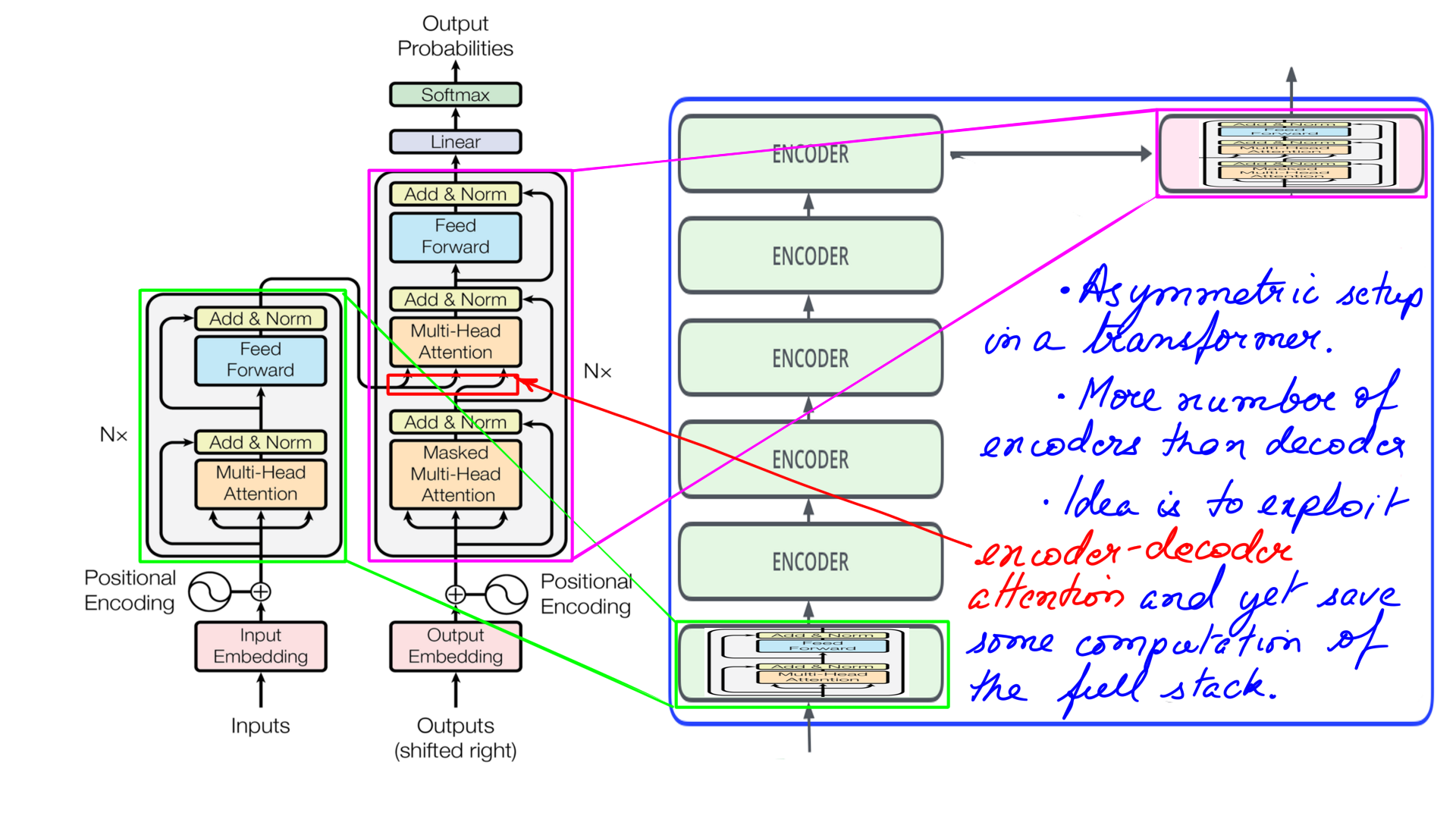
- Most pre-trained models drop either encoder or decoder from the transformer stack. BERT drops the decoder and GPT drops the encoder.
- However, our experiments have shown that a complete stack (encoder-decoder) generally outperforms a decoder-only or an encoder-only stack. T5 from google also supports a similar architecture for generally better results.
- The above transformer networks are called pretrained networks. BERT, GPT, T5 are examples of pretrained networks.
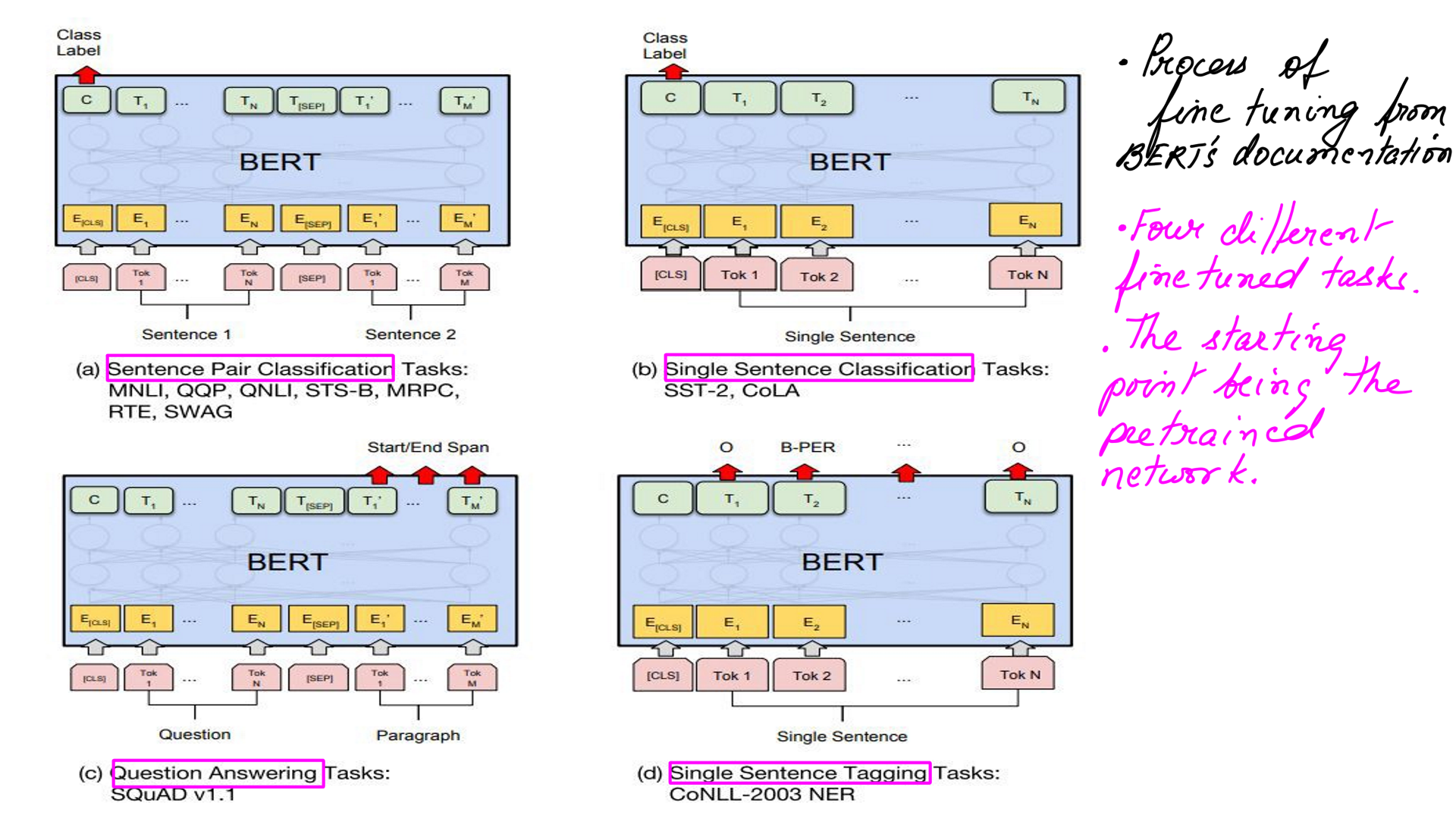
Fine tuning pre-trained networks
Maybe it is time for another quick analogy. Let’s say that I need a support staff to handle queries from our clients. When we do hire the support staff we assume a basic knowledge of conversational languages and current affairs. Post hiring, however, we need to train them on our specific processes. For e.g. if a particular issue has been solved for another client, this information is likely to be found in JIRA, LOGs, mailtrail e.t.c.
The pre-trained transformer of the previous section is analogous to basic knowledge of conversational languages.
The fine-tuned transformer is analogous to post hiring training specific to our processes. The fine-tuning takes for granted pre-training and does not have to start from scratch. Also, the flexibility to train the interns for different specific tasks.
Artificial Intelligence model based proactive and predictive decision making
This journey has been exhausting but fruitful. Finally, We treat the sequence of events captured by a tracer similar to a sequence of words in a sentence in NLP. Apart from that, from an Artificial Intelligence perspective, the setup is nearly identical.
- As discussed in the previous section, our transformer setup is asymmetric. We have more encoders than decoders.
- The reason being, we wanted to exploit encoder-decoder attention, without paying the price of a complete decoder stack. I believe T5 has a similar setup. It is a good trade-off in my opinion.
- The pre-training is standard. We have been doing performance work for quite some time. So we have lots of data. And the great thing about pre-training is it needs to be done off-line. This is the beauty of Transfer Learning.
- Elapsed time is the implicit time signal and no explicit positional encoding is applied unlike NLP.
- The only possible trap is running pre-training with less data that there are chances of overfit.

The Final Cut
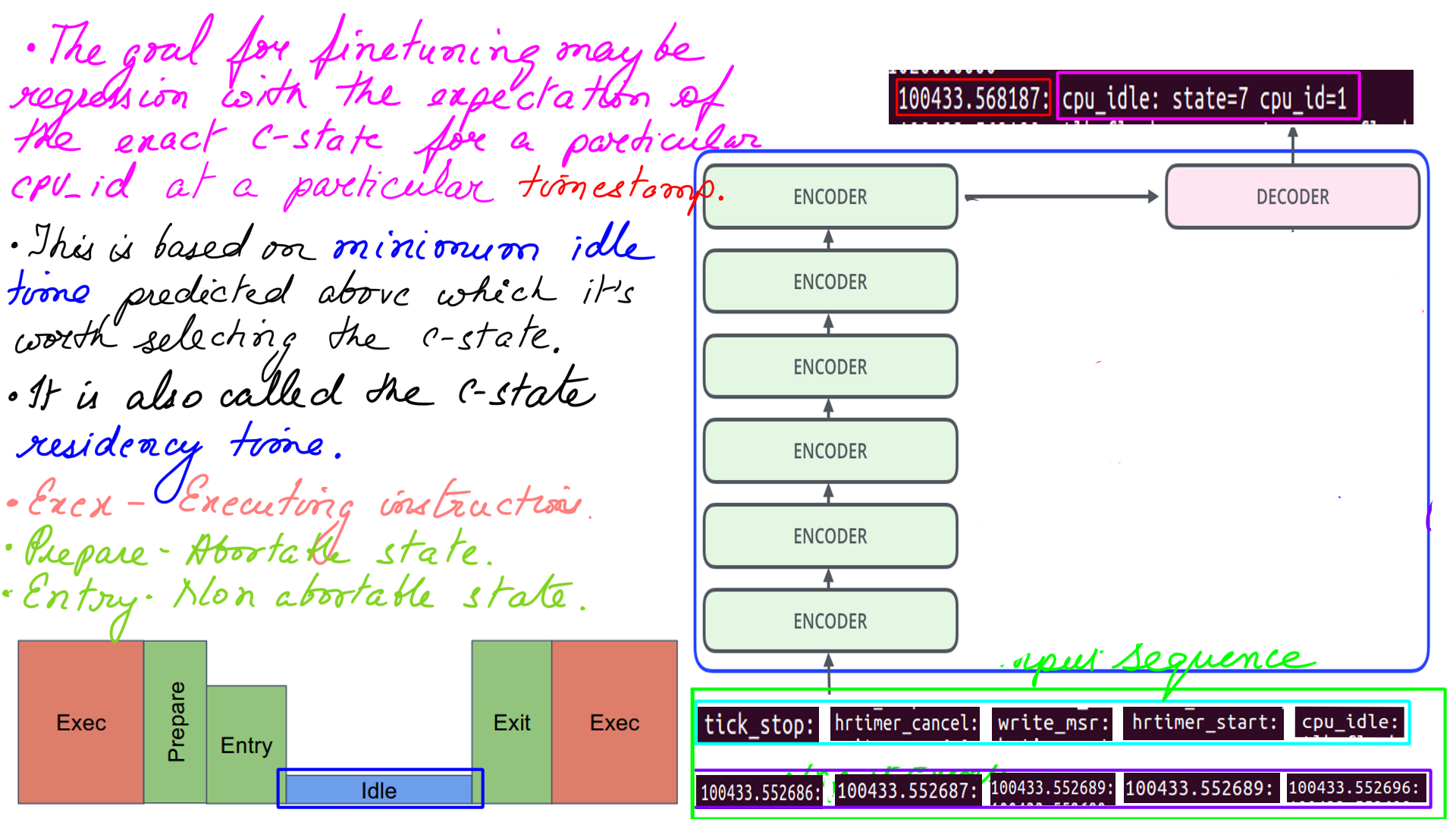
Regardless of the fine-tuning process, the pre-trained checkpoint remains the same. The fine tuning process itself can have many variations. The variations may be in terms of the goal, regression or classification with both having their pros and cons. I’ll illustrate a regression version here.
- The idea here is to select a state based on estimated idle time.
- The target residency is the minimum time the hardware must spend in the given state, including the time needed to enter it (which may be substantial), in order to save more energy than it would save by entering one of the shallower idle states instead.
Summary
In summary, this is the bird’s-eye view of the working of our system. We kept our focus on the core CPU for now but we plan to extend it to other components of the system. The Artificial Intelligence bit is quite interesting and we were helped a great deal by work done in the past on NLP. To the best of our knowledge, this has not been attempted before. Transformers are not the only model we have tried. We tried LSTMs with very encouraging results. However, as the data grew bigger, and with an inherent lack of parallelism in training, it got a tad bit slow. Inferencing was OK though. Last but not least, Deep Reinforcement Learning is another approach that we are currently integrating. We will post results in time to come. Last year has been phenomenal in terms of Artificial Intelligence in general and Natural Language in Particular. But many of these models can be used in cross-discipline domains. They are just waiting to be tried out.
References
- What every programmer should know about memory: (This is a definitive 9 part(the links for the rest of the parts are embedded in the first one.) article on how the hardware works and, how software and data structure design can exploit it. It had a huge impact on the way I thought and still do think about design. The article first came out in 2007 but it is still relevant which is proof that basics don’t change very often.)
- Intels documenation: (Intel’s documentation is the authentic source here. But, it is incredibly difficult to read. It is as if Intel’s employees were given a raise to make it “impossible to comprehend” kind of document.)
- Agner Fog: (He benchmarks microprocessors using forward and reverse engineering techniques. My bible.)
- Linux Source: (If you are going to trace your programs/applications then having the Linux source is a must. Tracers will tell you half the story, the other half will come from here. )
- Transformer: (Modern Natural Language processing, in general, must be indebted to Transformer architecture. We however, use an asymmetric transformer setup.)
- Performer-A Sparse Transformer: (This is as cutting edge as it can get. The transformer at the heart of it is a stacked multi-headed-attention unit. As the sequences(of words or System events or stock prices or vehicle positions e.t.c.) get longer, the quadratic computation and quadratic memory for matrix cannot keep up. Performer, a Transformer architecture with attention mechanisms that scale linearly. The framework is implemented by Fast Attention Via Positive Orthogonal Random Features (FAVOR+) algorithm.)
- Ftrace: The Inner workings ( I dont think there is a better explaination of Ftrace’s inner workings.)
- Ftrace: The hidden light switch: ( This article demonstrates the tools based on Ftrace.)
- BPF: ( eBPF or just BPF is changing the way programming is done on Linux. Linux now has observability superpowers beyond most OSes. A detailed post on BPF is the need of the hour and I am planning as much. In the meantime, the attached link can be treated as a virtual BPF homepage.)