
Meditating with microprocessors
- Artificial Intelligence based Hardware(Microprocessor) tuning: Implementing a very simple idea (part-1)
- A crashcourse in Microarchitecture and Linux CPUIDLE interface (part-2)
- Trading off power for UltraLowLatency (part-3)
- Artificial Intelligence guided Predictive MicroProcessor tuning (part-4)
- Introduction
- Is there a solution?
- Is there a smarter solution?: Artificial Intelligence model based proactive decision making
- Recognizing the pattern
- Transformer as the backbone
- Transfer Learning inspiration from NLP
- Fine tuning pre-trained networks
- Artificial Intelligence model based proactive and predictive decision making
- The Final Cut
- Summary
- Appendix:Tools of the trade (part-5)
Introduction
In the multi-part series titled Meditating-with-microprocessors, I demonstrate the use of Artificial Intelligence to tune microprocessors for Ultra-Low-Latency and Realtime loads. The techniques, in general, can be extended to other components of a computer system like storage devices, memory, etc. However, the article series and my work is currently restricted to Intel microprocessors only. In future, we may extend this to other hardware components of a computer system. This is a very specialized and intense field and hence I intend to break it down using the first-principles approach into simpler pieces of technology that are easy to understand. There are 5 parts to the series, Meditating with Microprocessors: An essentially simple idea(part-1) , A crashcourse in Microarchitecture and Linux CPUIDLE interface(part-2), Trading off power for UltraLowLatency (part-3) (part-3) , Artificial Intelligence guided Predictive MicroProcessor tuning (part-4), Appendix:Tools of the trade (part-5). In the balance then, this is a documentation of my journey navigating these utterly specialized fields ( microarchitecture and Artificial Intelligence ), how to marry them together, the issues I faced, the respective solutions, what (how much) are the benefits if any, and what to have in the toolbox.
Meditation and microprocessors: An extremely simple idea
The idea is so simple, it is actually ridiculous. Also, it pays to know of an analogy to compare it to just in case the technology sounds complicated. In our daily lives, we go through cycles of work time and relaxation ( I’ll call it meditation, you may call it meditation or sleep ). The work time is our livelihood, pays our bills but also stresses us out. The meditation time is the recuperation time. It helps us stay sane.
As it turns out, microprocessors, for lack of a better phrase, have a similar sleeping pattern. In fact, modern microprocessors have a very sophisticated sleeping pattern. When they have work to do (execute instructions) they are in a waking state (duh) getting vital work done but expending much energy. On the other hand, when there is a lack of work (no instructions to be executed) they spiral into deeper and deeper sleeping states with the intention of saving power and conserving energy. The catch is that the deeper they go into sleep states, the more is the time they take to come back to full awareness to execute instructions again.
MicroProcessor C-states
- This is c-states as documented in the Intel 8th and 9th datasheeet manual.
- The actual states may differ depending on the exact model of the Microprocessor.

- This can be queried using the “/sys/devices/system” interface on Linux
- The actual states may differ depending on the exact model of the Microprocessor.
- Names can be confusing too. So there are 9 c-states(c-state0-c-state8) and they are called C0,C1,C1E,C3,C6,C7s,C8,C9,C10.

- Each of the green lines ending on a positive number represents entry into a c-state.
- Again, Each one of the green line ending on a negative number (-5) represents the exit from the previous c-state.
- The value returned to denote an exit is actually 4294967295 which is -1. size_t is an unsigned integral type, it is the largest possible representable value for this type

- The C0 is the state where the code is executing. So there is O ‘wakeup latency’. ‘Wakeup latency’ refers to the time it takes for the microprocessor to wake up from a sleep state. What you see marked in red is application latency.
- The rest of the picture c-state1(C1) to c-state8(C10) refers to the ‘wakeup latency’ and it goes up as the microprocessor goes into deeper c-states
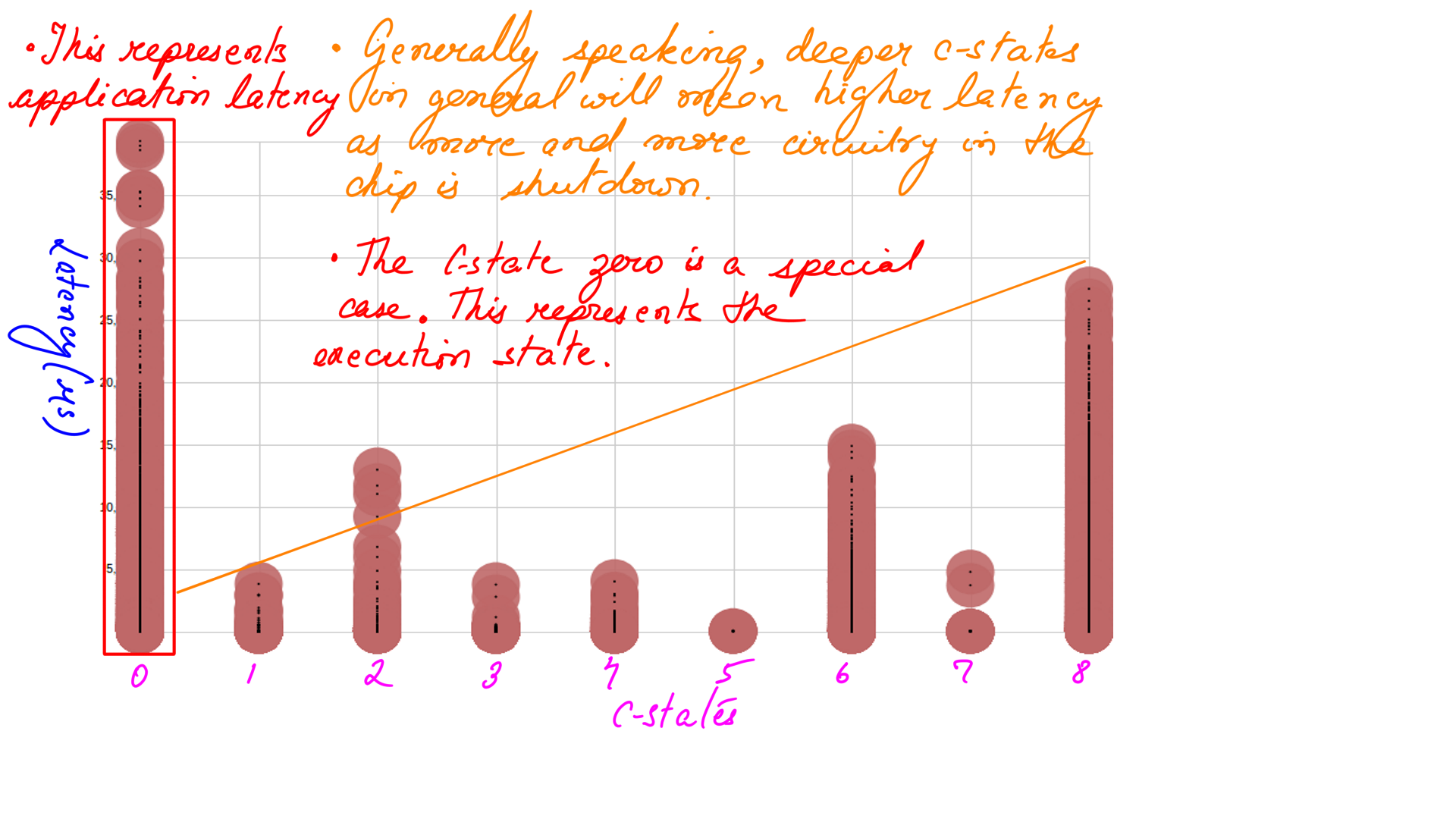
A quick Summary of wakeup_latency:
Hopefully, the above illustrations were helpful in understanding the crux of the matter, and references to meditation were not distracting. Here is a quick summary, modern Microprocessors switch states(deeper c-states as illustrated in figure-{1,2,3,4}) to save energy when there are no instructions to execute. And fling back to C0 when there are instructions to execute. This flinging back time is called ‘wakeup_latency’ and is higher for deeper states as illustrated in figure-4. And this ‘wakeup_latency’ is problematic for Ultra-Low-Latency applications. The source of the problem
Artificial Intelligence based Hardware(Miroprocessor) tuning
If you consider figure-3 there were close to 25000 transitions (give or take) in a stretch of 15 seconds. Each of those costing valuable hundreds of microseconds. The effect can also get magnified because there might be multiple application threads vying for microprocessor resources. It can get worse. There might be a Domino effect of these occurrences. There is a specific term coined for the Domino effect in the software world. I believe it is called coordinated omission and here is a great reference to it.
- Is there a microprocessor setting that restricts spiraling into deeper c-states so that wakeup latency is effectively ‘0’? Yes, there is, but it will drain a lot of energy/power and may be detrimental to the microprocessor’s health in the long run ( Similar to life without meditation ).
- Can we look at the historical load and predict when it might occur again. If yes, then can we configure it to a setting which is suited to Ultra-Low-Latency or Realtime workloads. The answer to that is a huge yes. Understandably this has to be done on the fly at runtime using the software controls provided by the Hardware and the OS.
- This is one of the things that our software intends to do. So once we have the load being predicted by Artificial Intelligence based model, we tune the microprocessor to the settings which reduces latency if the goal is to lower latency.
- We reset the settings to power save(normal mode) when the high load had tided over. As of now, the implementation is only for Intel microprocessors. But in the future, we believe we can extend it to Memory chips, HDDs and SSDs, and so forth.
- There is something else. Just like there is a unique signature that every person has, in a similar manner there is a unique signature for a particular load. This signature can be recognized using pre-training using techniques similar to transfer-learning in NLP and BERT.
Summary
In summary then, modern microprocessors have power saving states they enter into when there is no work to do. All very good, till you consider that they have to get back to “full click” when they have to perform work. Ordinarily, this is not a problem but for some latency(performance) sensitive application. This approach is reactive or causal. Can we make this proactive based on some Artificial Intelligence based load prediction. Rest of the articles in the series is an under-the-hood look at how the processors interface with software(OS) and if there is a case to be made for Artificial Intelligence. Also there are things to explore for performance minded programmers. So get your hands dirty.
References
- What every programmer should know about memory: (This is a definitive 9 part(the links for the rest of the parts are embedded in the first one.) article on how the hardware works and, how software and data structure design can exploit it. It had a huge impact on the way I thought and still do think about design. The article first came out in 2007 but it is still relevant which is proof that basics don’t change very often.)
- Intels documenation: (Intel’s documentation is the authentic source here. But, it is incredibly difficult to read. It is as if Intel’s employees were given a raise to make it “impossible to comprehend” kind of document.)
- Agner Fog: (He benchmarks microprocessors using forward and reverse engineering techniques. My bible.)
- Linux Source: (If your going to trace your programmes/applications then having the Linux source is must. Tracers will tell you half the story, the other half will come from here. )
- Transformer: (Modern Natural Language processing, in general, must be indebted to Transformer architecture. We, however, use an asymmetric transformer setup.)
- Performer-A Sparse Transformer: (This is as cutting edge as it can get. The transformer at the heart of it, is a stacked multi-headed-attention unit. As the sequences(of words or System events or stock prices or vehicle positions e.t.c.) get longer the quadratic computation and quadratic memory for matric cannot keep up. Performer, a Transformer architecture with attention mechanisms that scale linearly. The framework is implemented by Fast Attention Via Positive Orthogonal Random Features (FAVOR+) algorithm.)
- Ftrace: The Inner workings ( I dont think there is a better explaination of Ftrace’s inner workings.)
- Ftrace: The hidden light switch: ( This article demonstrates the tools based on Ftrace.)
- BPF: ( eBPF or just BPF is changing the way programming is done on Linux. Linux now has observability superpowers beyond most OSes. A detailed post on BPF is need of the hour and I am planning as much. In the meantime, the attached link can be treated as virtual BPF homepage. )