
Introduction
In this multi-part series we look at Neural Machine Translation, the technology behind how machines understand humans. The first of which(current article) is a completely pictorial and a non technical take on the technology and its potential. The rest of the parts will be a rigorous under-the-skin (math,code and logic) look at Neural Machine Translators, Attention and, the cherry on the cake Googles Neural Machine Translators. The rigorous under-the-skin (math,code and logic) look will enable you to recreate the system for your own needs.
In the current article, we take a highly simplified, completely pictorial look at Artificial Intelligence(AI) based translation systems from one Natural Language to another. Natural language, as in the way humans speak and how far have we come in designing machines that understand and act on it. Once you have a solid understanding of systems like these, we take a look at where are we currently applying it to(case studies), to broaden the horizons.
Artificial Intelligence(AI) is a vast subject. To explain in short and without getting technical is even more difficult. However, if we confine ourselves to examples in a particular domain, it might be a lot easier. Once we understand AI in the context of our chosen example, we could then broaden the horizon. In our case, we consider software that translates text from one language to another. Let’s look at a quick history first.
There are multiple parts to the article:
Machine Translation: A quick history
Machine Translation(MT)
On a basic level, MT performs simple substitution of words in one language for words in another. But that alone cannot produce a good translation of a text because recognition of whole phrases and their closest counterparts in the target language is needed. Have you ever watched a movie with subtitles being so bad it actually distracts? A few years back I have had the crass luck of accidentally watching a movie with subtitles turn on for the Hindi language. I am wondering if I can call it hilarious or scary, maybe both. A serious plot-based movie’s literal translation of “holy shit” in Hindi forever ruined my movie-watching experience.
The context of what is being said is extremely vital to do a decent translation. Let's look at an example. Out of many possibilities, one correct literal translations of “Higher ape” to Hindi would be “ooncha bandar”, translated back to English it becomes “Tall monkey”. The last example completely loses the context of what is being said. The genetic ancestral context is completely lost.
Rule-based Machine Translation(RBMT)
An RBMT system generates output sentences (in some target language) based on morphological, syntactic, and semantic analysis of both the source and the target languages involved in a concrete translation task. This is difficult, to say the least. And the rules for a language is not reusable for another.
Statistical Machine Translation(SMT)
Statistical machine translation was re-introduced in the late 1980s and early 1990s by researchers at IBM’s Thomas J. Watson Research Center. Roughly translated and simplified, SMT measures the conditional probability that a sequence of words Y in the target language is a true translation of a sequence of words X in the source language. The problem with SMT is that the use of probabilities to understand the complex structure of language was a bit too simplistic. They have had moderate success and were used nearly a decade back.
Neural Machine Translators(NMT)
The object of our discussion in the current article and the accuracy has to be seen to be believed. To be precise, what I am presenting today is Neural Machine Translators(NMT) with Attention. Like most(not all) AI-based models, NMTs also learn by looking at examples, in our case example translations. In this respect, they are similar to SMTs. However, their internal representation where they store their understanding is a neural network instead of a probabilistic one.
Neural Machine Translators(NMT) with Attention
There are multiple parts:
- Process of training
- Jump to accuracy first
- Generality
- Practice makes the NMT perfect
- Hindi to Engish Examples
- Byte pair Encoding
- Could not resist having some fun
- French to english
- Other Languages
Process of training
- Ignore the blue rectangle for now.
- Words are converted to their numerical representation called embeddings before being fed into the NMT.
- Once you have trained with enough data, the NMTs start to understand the 2 languages in question. In figure-1 its Hindi to English.
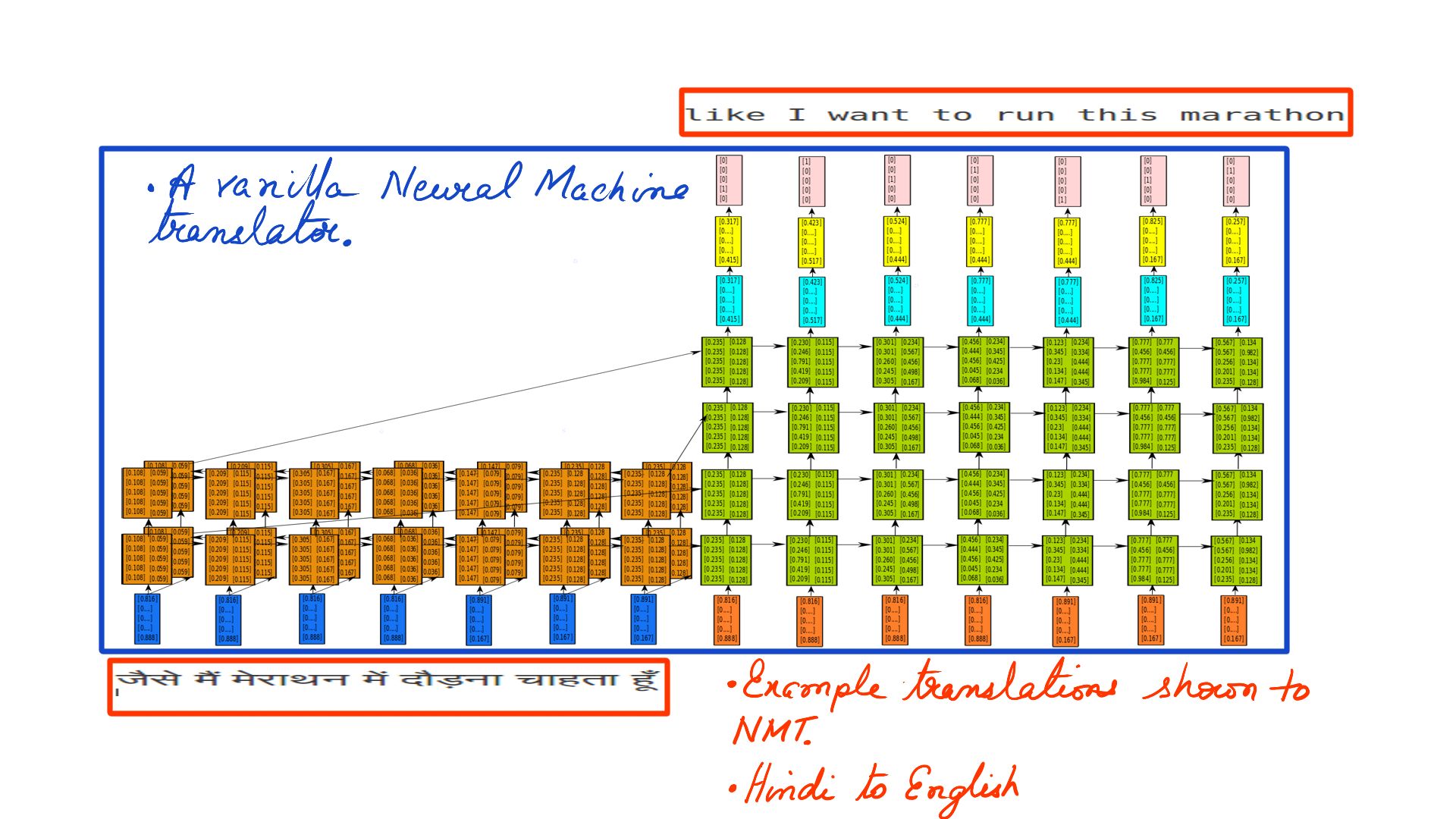
- Ignore the blue rectangle for now.
- Once you have trained with enough data, the NMTs start to understand the 2 languages in question. In figure-2 its French to English.
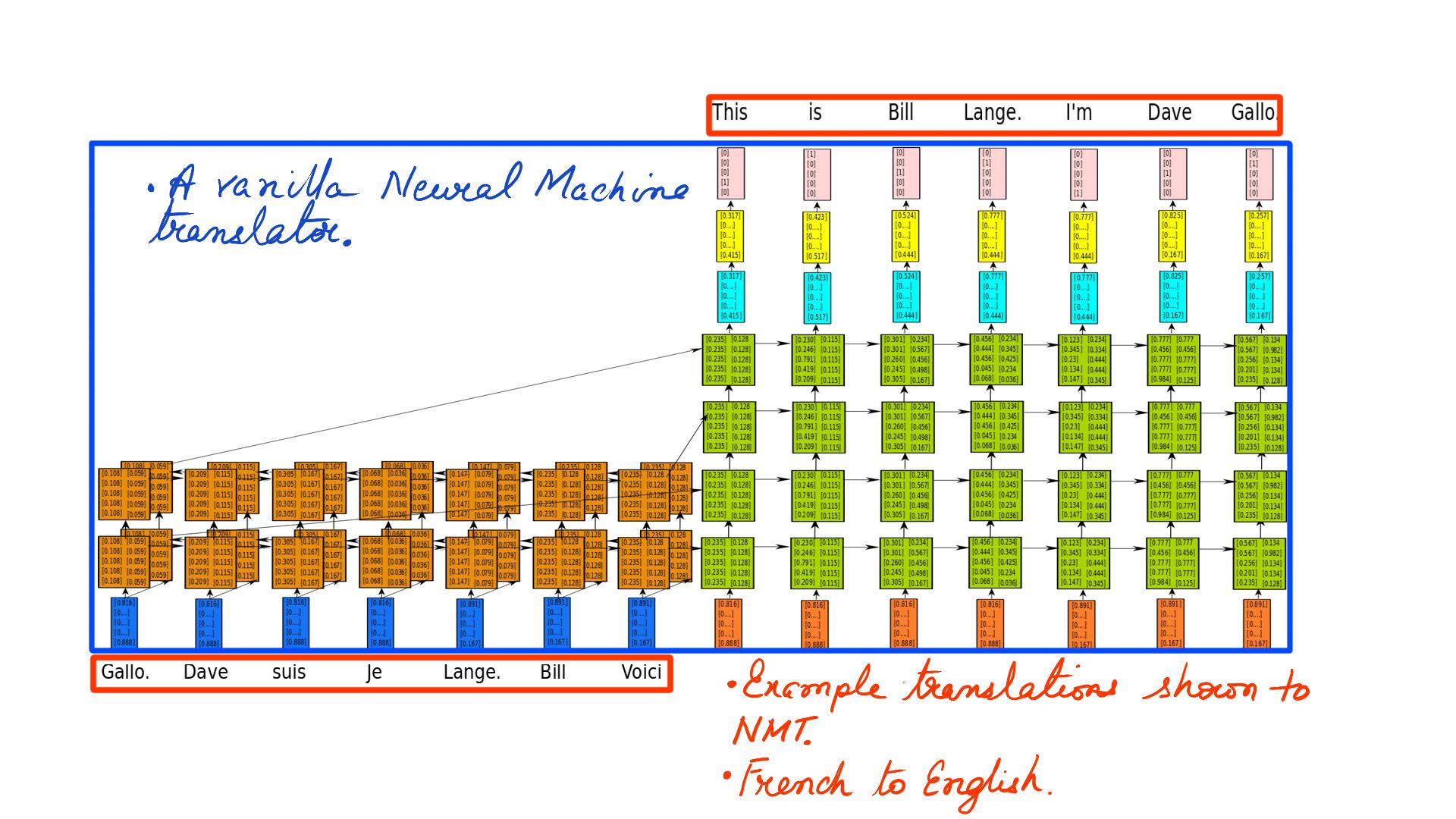
- Ignore the blue rectangle for now.
- Once you have trained with enough data, the NMTs start to understand the 2 languages in question. In figure-2 its Vietnamese to English.
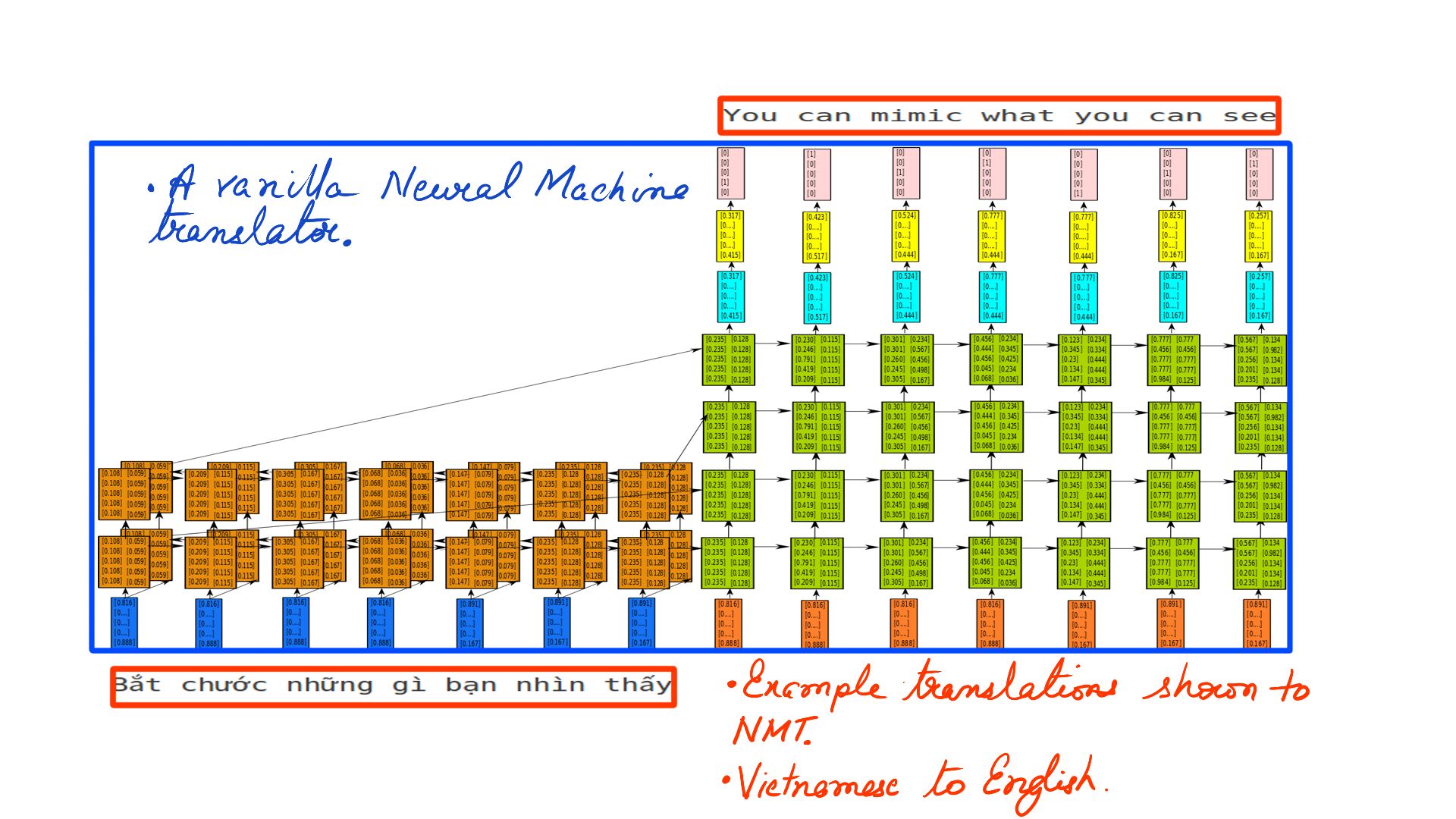
- The training has to be meticulous, in that, the data has to be as accurate as possible. Various measures of accuracy checks have to employed to see if the desired accuracy has been achieved. Some data has to be kept aside for testing that is not shown during training. That and more in the deep technical analysis the articles that follow.
Jump to accuracy first
To hell with the theory, show me the accuracy first. If you have not seen a system like this before, the results are nothing but magical.
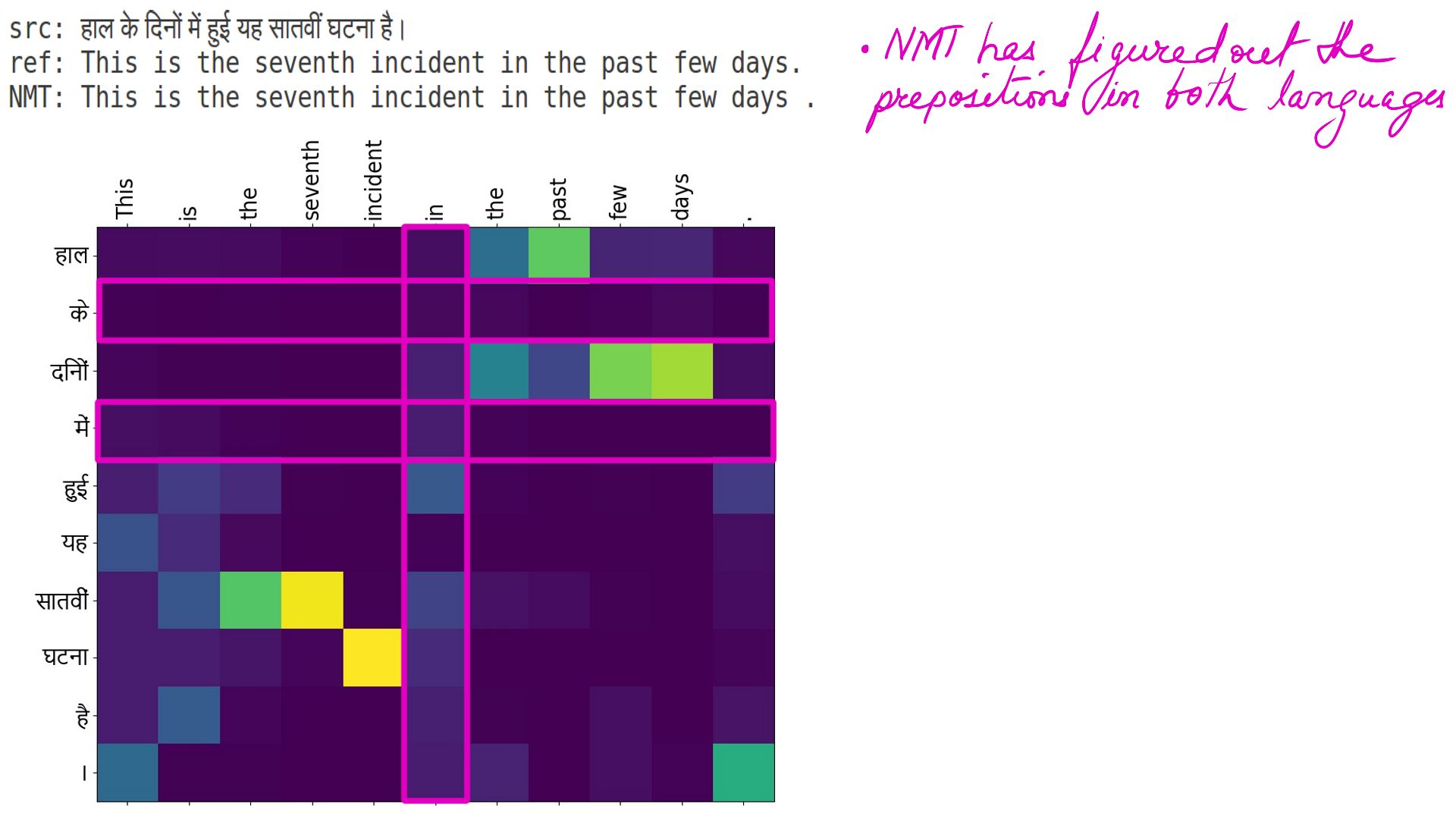
- Take a pause, and imagine yourself translating between any 2 languages you know. It Happens subconsciously, but pause and analyze the process. You read the source sentence first, and then as you translate you keep your focus on the phrases/words and the surrounding words from the source sentence . Attention-based NMTs are built with the same idea.
- But what is that matrix?

- During the training, The NMT jots down its understanding of the 2 languages in it’s internal LSTM based neural network.
- I’m merely visualizing it specific to this example translation.
- It illustrates the attention(pun intended) paid on the source words/phrases to translate to target words/phrases.
- The process is very similar to human Translators.

- The highlighted portions of a matrix illustrate the specific word/phrases within the sentences.
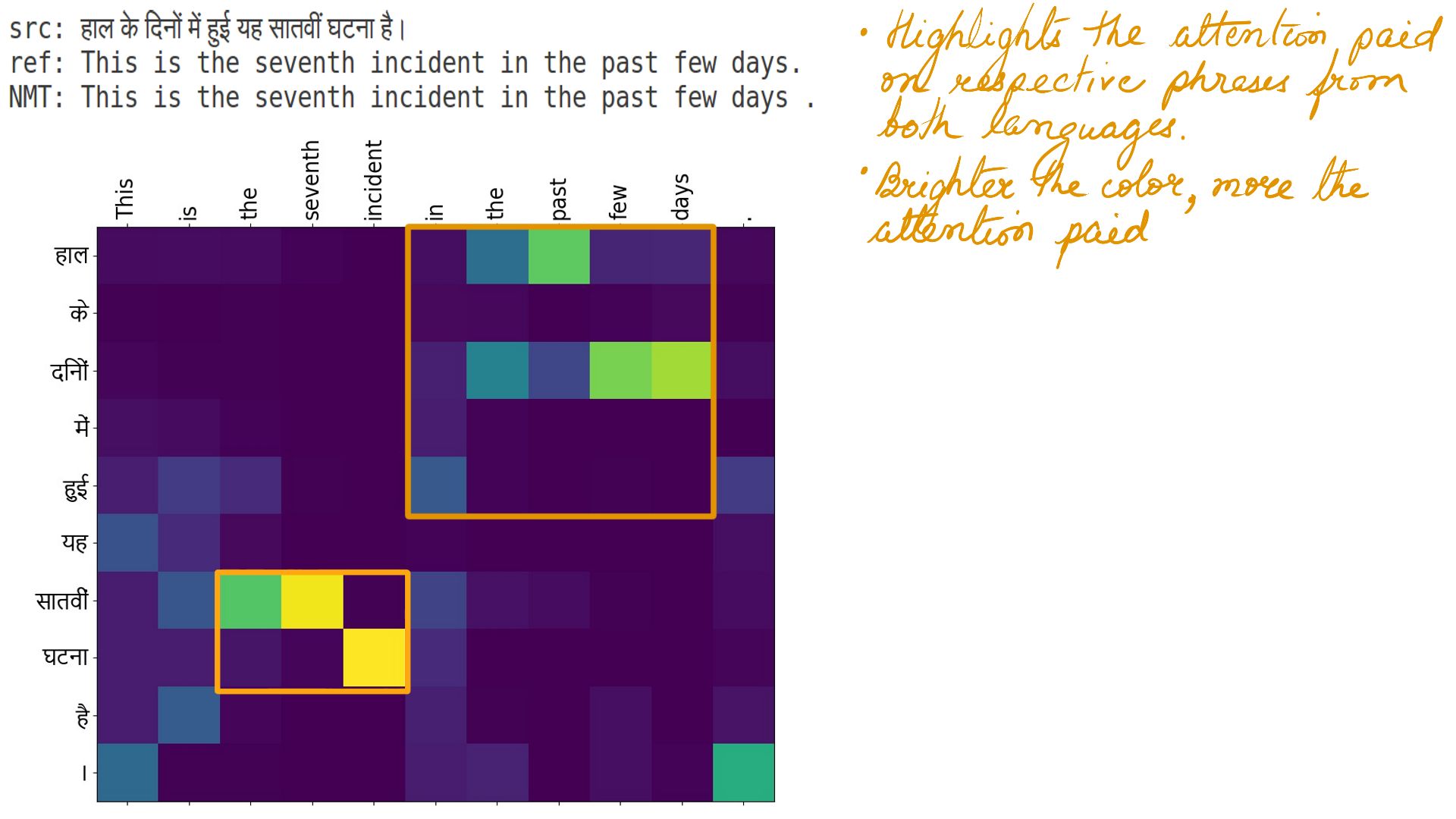
- The highlighted portions show prepositions in both languages.
- Well, it should come as no surprise that the NMTs can work out “Parts of speech” of a language and not just the prepositions.
Generality:
If the accuracy is convincing then, let’s talk about generality. As you can witness yourself, the model architecture remains the same but when trained with different datasets “it acquires knowledge” about that data set and starts making predictions, in our case translations. This probably the most important reason why AI is going to redefine how programming is done in the future.
Practice makes the NMT perfect:
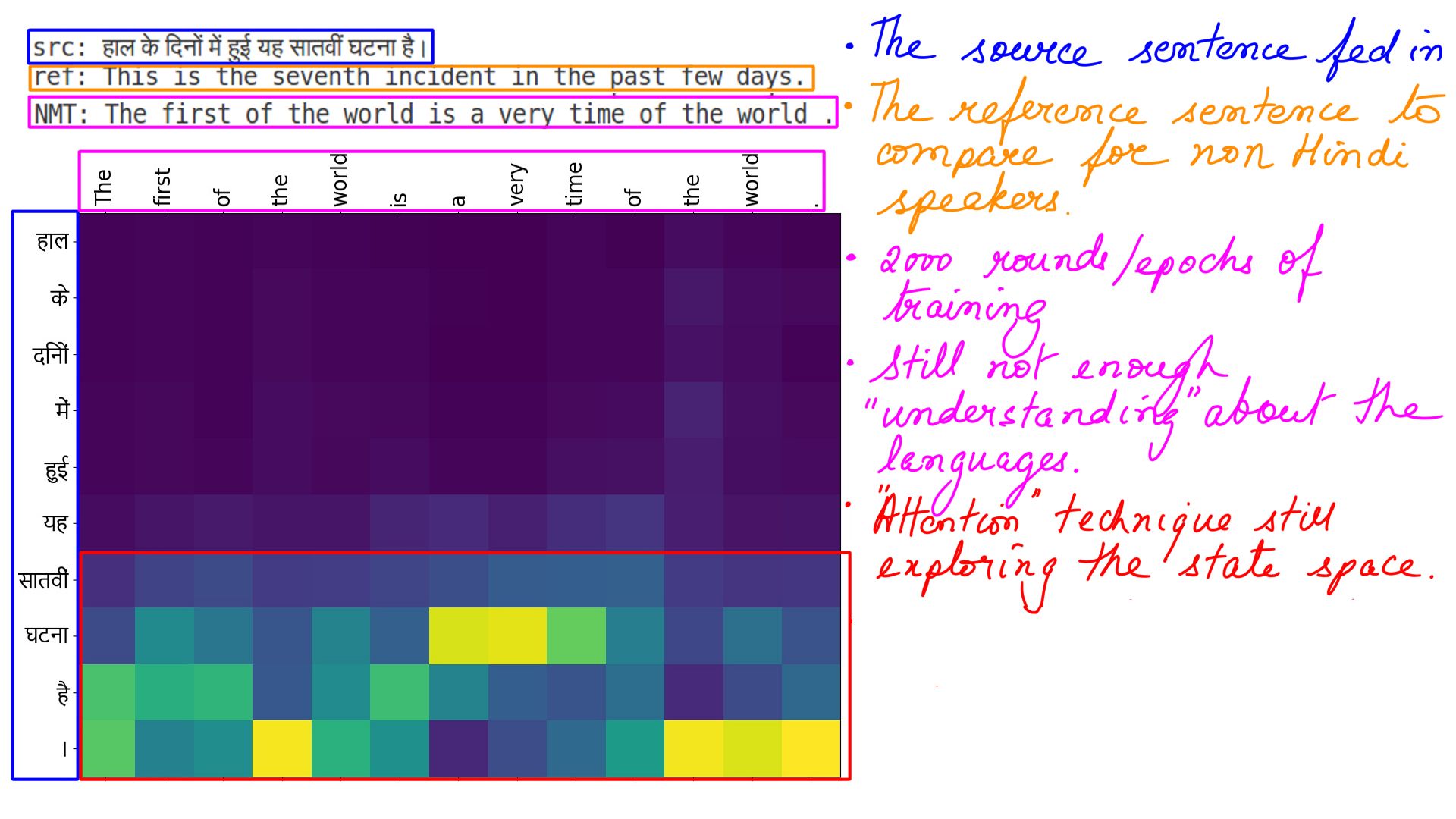
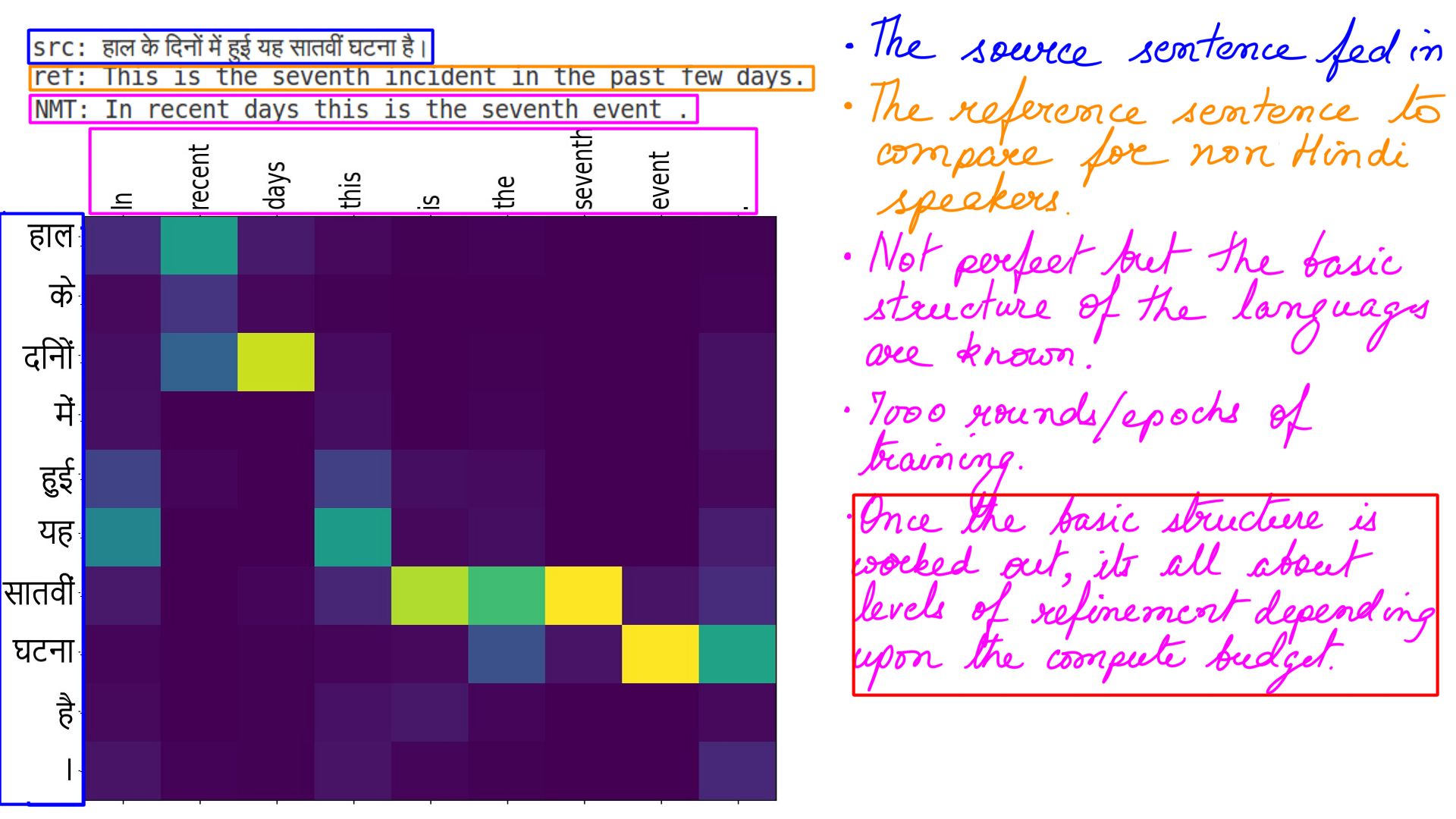
The next couple of pictures illustrate the gradual attainment of knowledge by the NMT as we increase the training rounds.
- 500 rounds/epochs of training.

- 1000 rounds/epochs of training.
- The most important aspect being the difference between what is predicted by the NMT and what is the ground truth.
- This difference which we historically call error or loss is “communicated” back to the NMT.
- The NMT promptly adjusts its internal state and explore other possibilities.
- This is what “we”(scientific community) refer to as learning, and we think(well, the same scientific community) this learning “somewhat” mimics how human brain work.

- 2000 rounds/epochs of training.
- 5000 rounds/epochs of training.

- 7000 rounds/epochs of training.
- 10000 rounds/epochs of training.

- Incremental comparison
- The picture on the right has a far better distribution of attention weights then the one on the left.

Hindi to Engish Examples
Why Hindi? I could have chosen any language where data was easy to come by. I did not because, with Hindi I can double up as a human evaluator. This is a language we speak at home, to be more precise, it is a mix of English, Hindi, and Kannada. My Hindi skills are, at best average but good enough for evaluating the translations.
The data for Indian languages are surprisingly difficult to come by. The data that is used for this blog, does not belong to Stillwaters or Stillwaters’ client by any means. This has been personally sourced for this blog from Charles University, Czech Republic and Statistical Machine Translation. When Stillwaters or me personally work with a social media giant, fintech giant or one of the formost chipmaker, the data is sourced by their team and, one can make guarantees about it’s accuracy. Infact, they have dedicated team(s) which exists solely for this purpose. However, that data cannot be shared for various reasons. The same cannot be said about personally sourced dataset like the ones I’m using for this blog. The Example below shows an example of a really bad translation. It isn’t even a good literal translation. In fact it is an incorrect statement in English.
“मलेरिया के मुकाबले।”
“than are put into malaria.”
One bad translation might be an oversight but there are many bad sample translations. One too many to ignore. Long story short, the accuracy of the translations can be much much much better with better data.
Byte pair Encoding
- BPE Stands for Byte Pair Encoding. It was originally developed for compressing data. While it is still used for compression in Natural Language processing, it has a few more important advantages.
- Intuitively speaking, this is how words are made up in many languages. Longer words are made up of shorter syllabic sounds.
- Let’s say that we train a model on words like “walk”, “walking”, “walked” and it begins to understand the relationship between the words. However, a similar relationship between “talk”, “talked”, “talking” isn’t clear by analogy if it has not trained on all the words before. This can be remedied by breaking words into smaller syllabic tokens. Words like “walking” can be broken down into “walk” and “ing”. Similarly “walked” can be broken down into “walk” and “ed”. This also clarifies the meaning of “ed” and “ing” to the model and by analogy, the model is able to infer the meaning of talking even though it has never encountered the word before.
- Another positive side effect is, rare words not seen at training time can still be recognized because they are made up of smaller syllabic tokens.
- Lastly, it improves accuracy.
- Now, even if you have not understood the above points, just remember the words are broken down into smaller syllabic tokens before being fed into the NMT.
- Rest of the examples are in BPE encoding.
- Hindi to english:ex-1
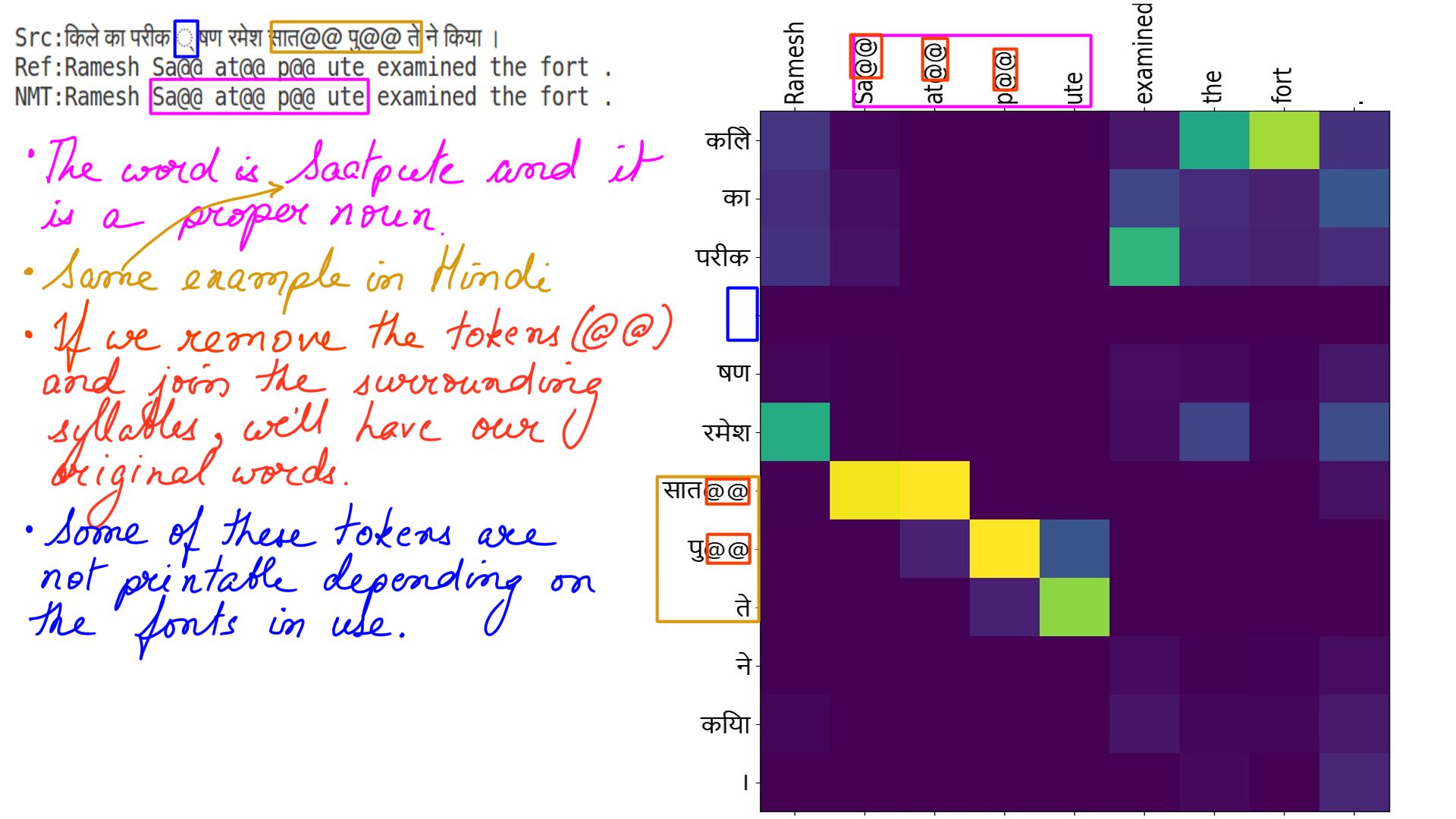
- Hindi to english:ex-2
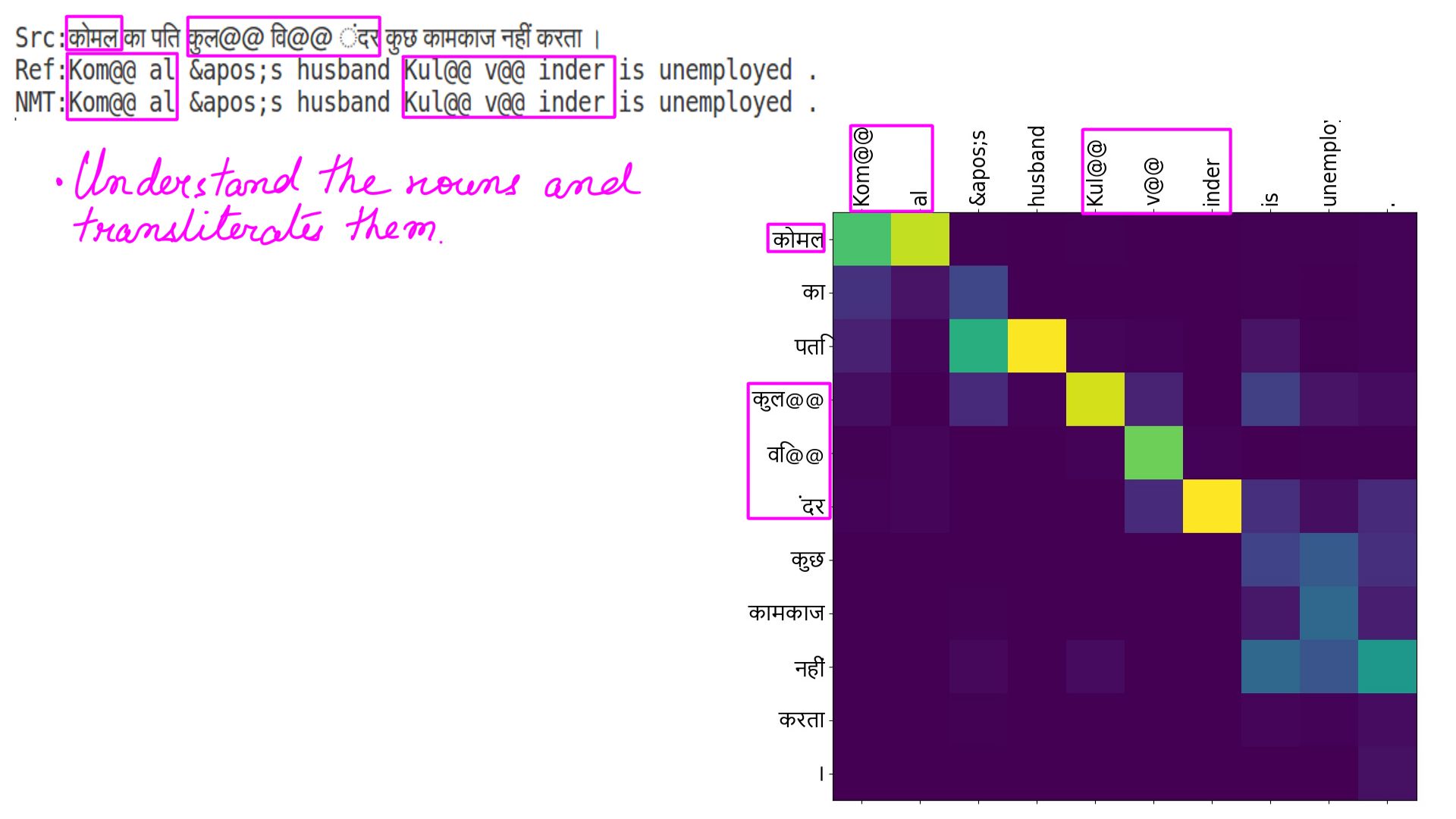
- Hindi to english:ex-3
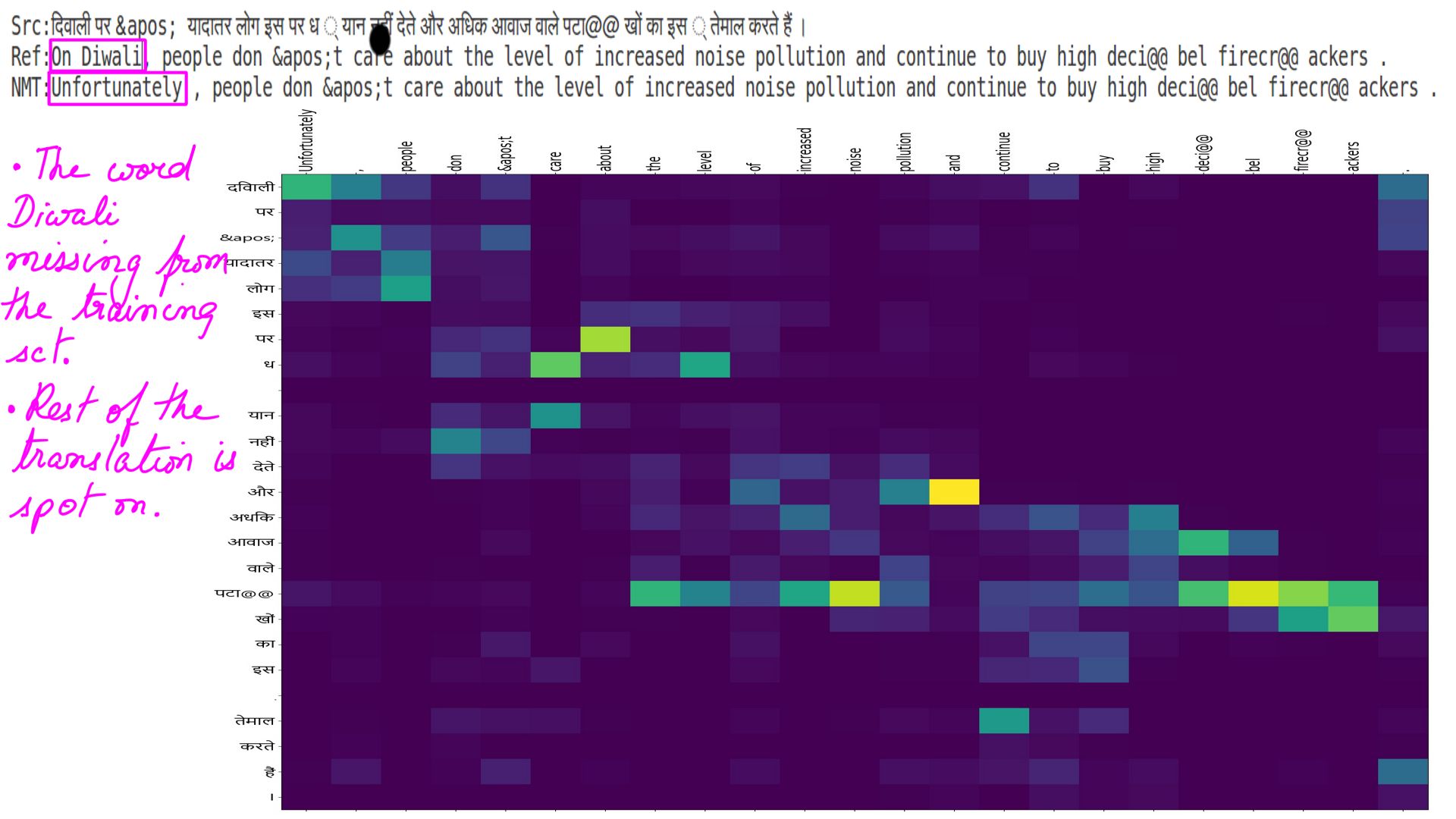
- Hindi to english:ex-4
- The remaining examples are long and complex sentences. We could solved them only post the arrival of Attention.
Src:”ल@@ ले@@ याल सत@@ वारी के ना@@ यब सर@@ पंच चैन सिंह ने बताया कि यहां आने वाले श ् रद ् धा@@ लुओं के लिए ल@@ ंगर की भी व ् यवस ् था है ।”
Ref:”Nay@@ ab Sar@@ pan@@ ch of Lal@@ ey@@ al Sat@@ wari , Cha@@ in Singh said that a L@@ ang@@ ar has also been organised for the pilgrims visiting this place .”
NMT:”Nay@@ ab Sar@@ pan@@ ch of Lal@@ ey@@ al Sat@@ wari , Cha@@ in Singh said that a L@@ ang@@ ar has also been organised for the pilgrims visiting this place .”
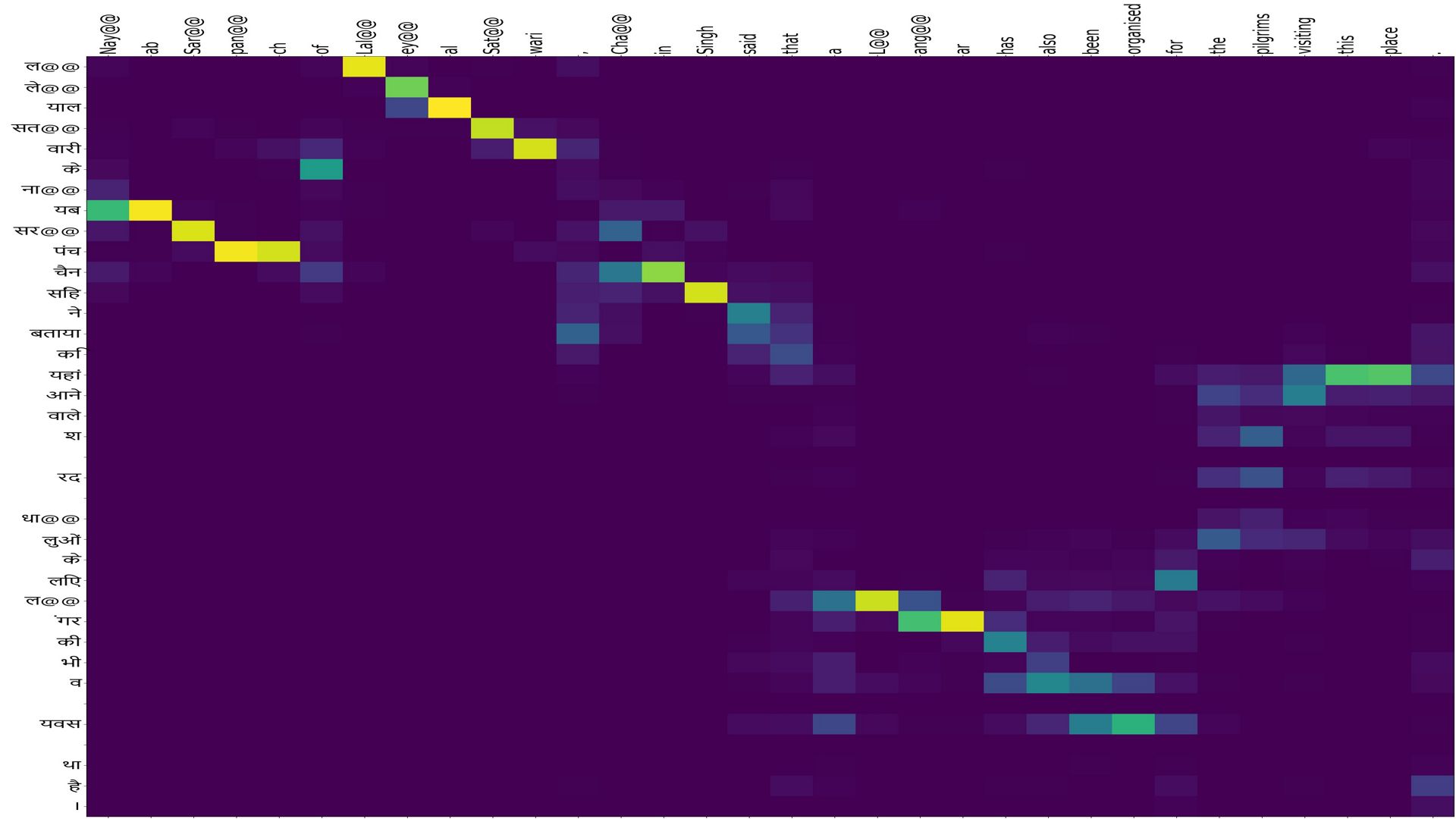
- Hindi to english:ex-5
Src:”शुक ् रवार को जय@@ राम ने कहा कि अदालतों का अपनी सीमाएं पार करते हुए अफसरों और सरकार के काम को अपने हाथ में ले लेना ठीक नहीं है ।”
Ref:”On Friday J@@ airam said that it is not right for the Courts to exceed their powers and take the job of the officers and the Government into their own hands .”
NMT:”On Friday J@@ airam said that it is not right for the Courts to exceed their powers and take the job of the officers and the Government into their own hands .”
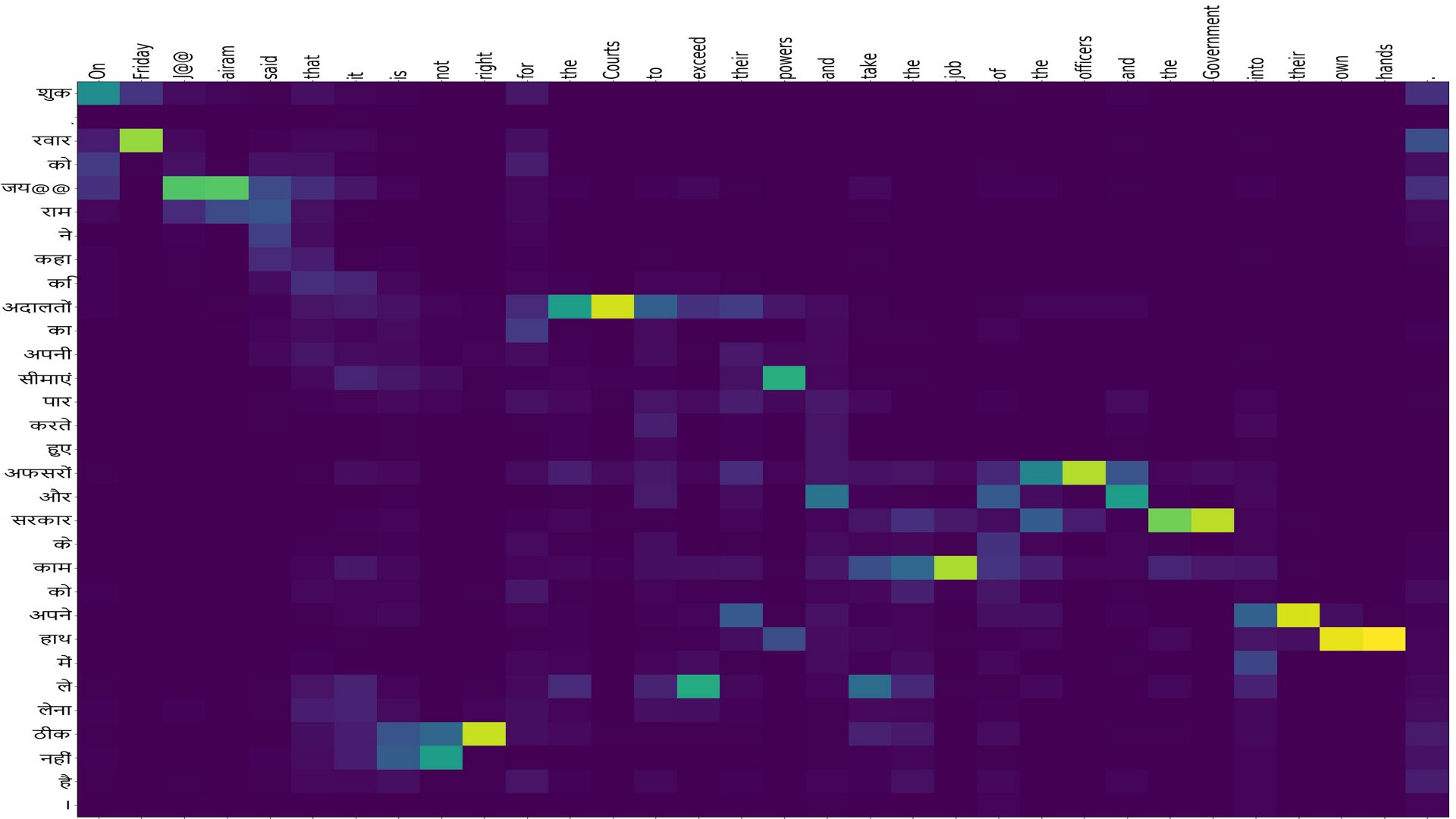
Could not resist having some fun
The premise of article is about bad and out of context subtitles. Just couldn’t stop my self from indulging in a little fun.
- Hindi to english:ex-6
- Just in case, I am not quoting a former president of United States.
Src:”बड ़ े-@@ बड ़ े देशों में छोटी-@@ छोटी बातें होती रहती हैं ' ।”
Ref:”In big countries , little things like these keep happening .”
NMT:”In big countries , little things like these keep happening .”
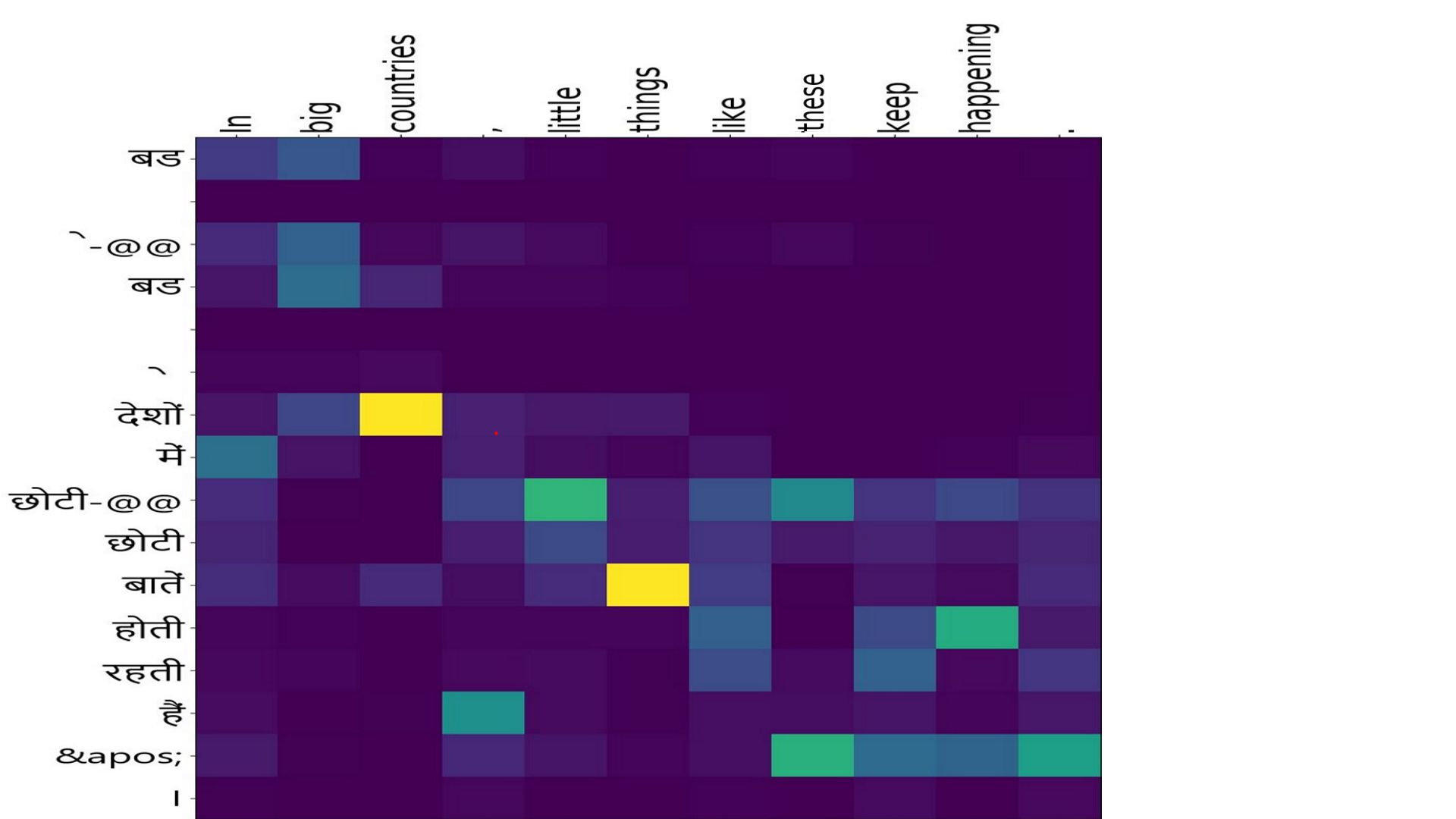
- Hindi to english:ex-7
- Neither am I quoting Paulo Coelho.
Src:”इतनी शि@@ द@@ अत से मैं तुम ् हे पाने की कोशिश की है , की हर ज़@@ ारे ने मुझे तुमसे मिलाने की सा@@ ज़@@ ि@@ श की है ।”
Ref:”I have tried to get you with all my heart , that the whole universe has con@@ sp@@ ired to introduce me to you .”
NMT:”I have tried to get you with all my heart , the whole universe has con@@ sp@@ ired to introduce me to you .”
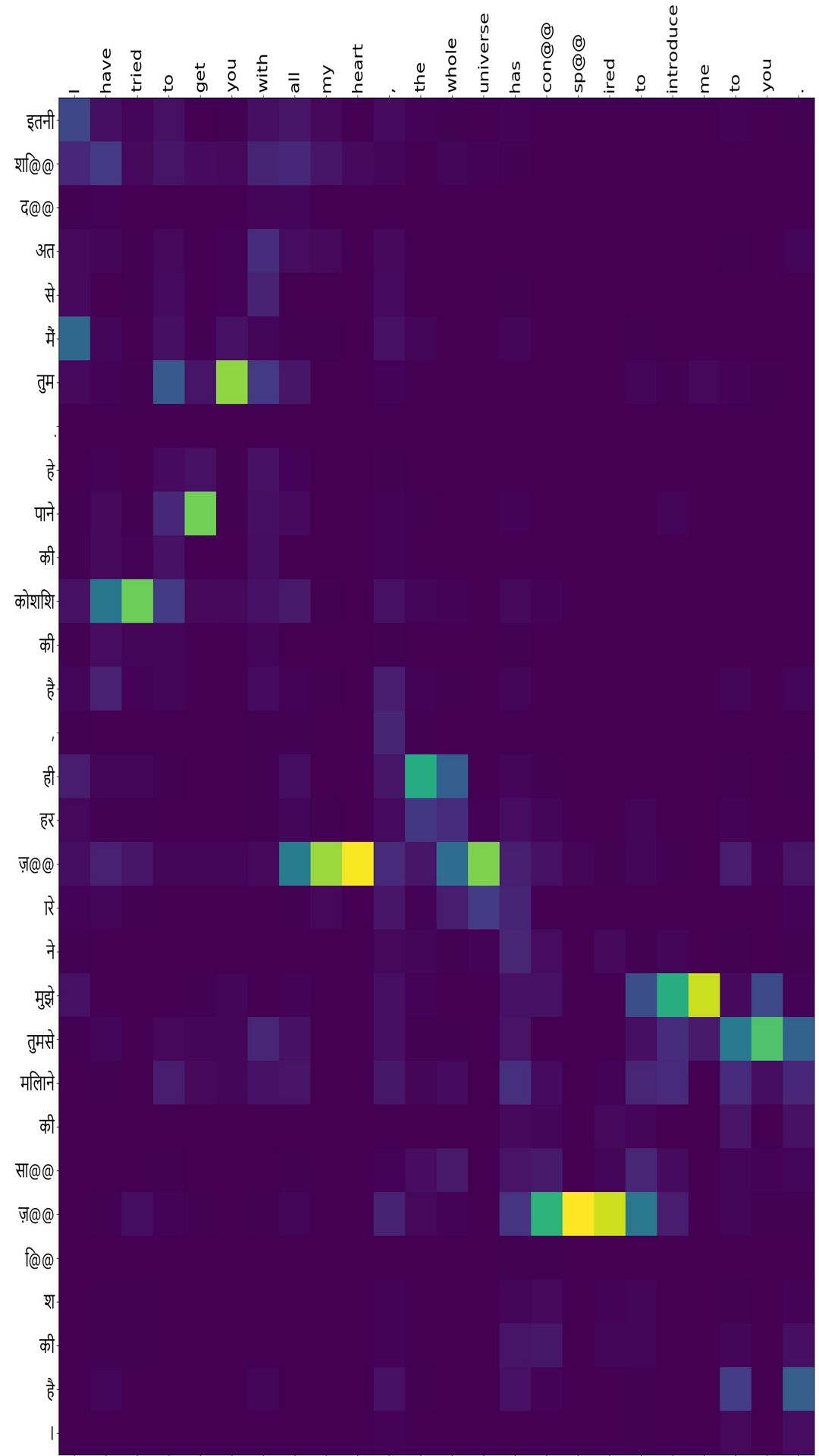
- Hindi to english:ex-8
- And he’s the “desi” He-Man.
Src:”ब@@ सं@@ ती इन कुत ् तों के सामने मत ना@@ चना”
Ref:”Bas@@ anti don 't dance in front of these dogs .”
NMT:”Bas@@ anti don 't dance in front of these dogs .”
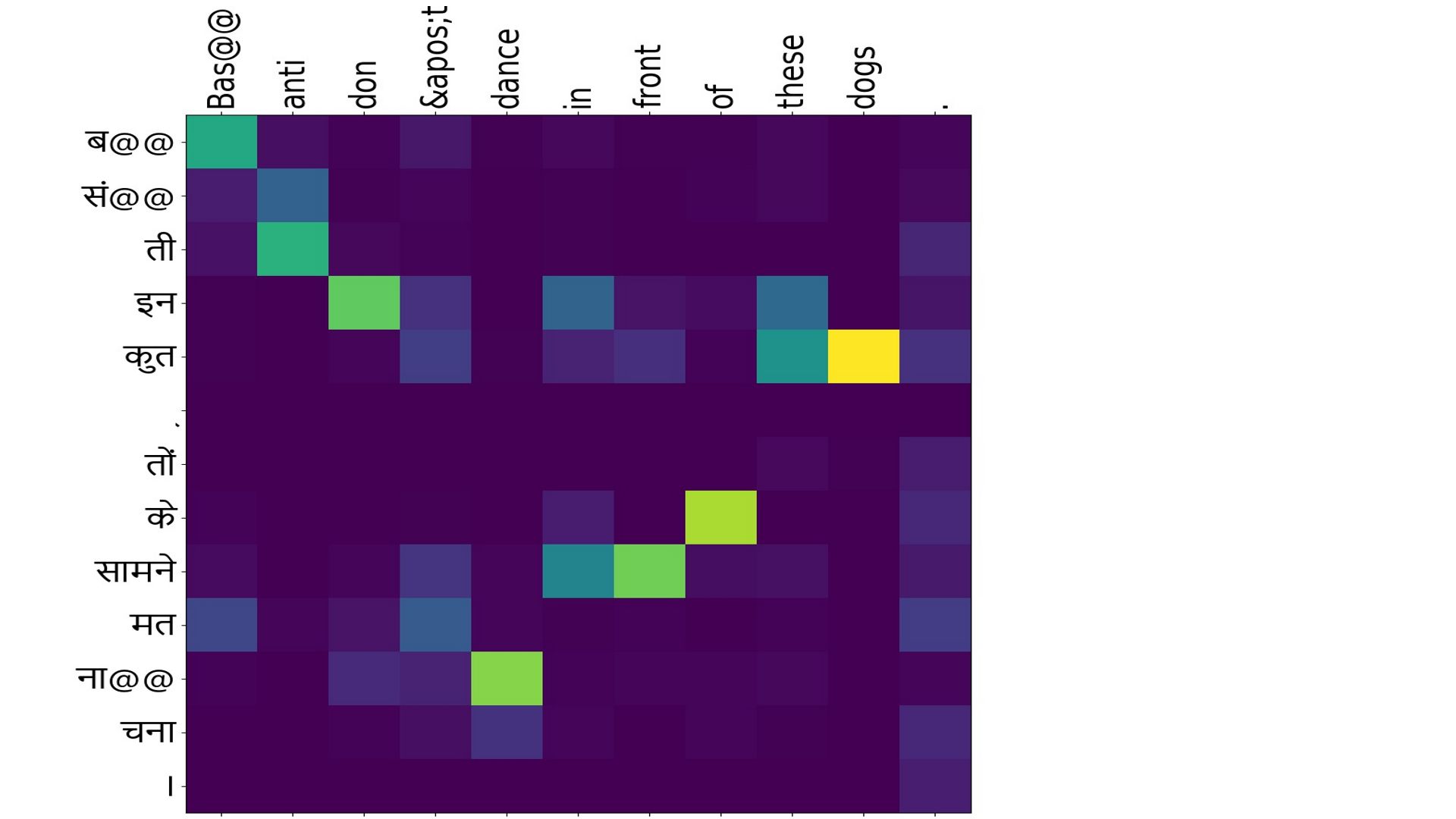
French to english
My knowledge of the French language is rudimentary. I learnt French for understanding NMT results. That is the limit of French knowledge. However, one of the things that stood out for me in French were adjectives. In English, adjectives are pretty easy to use. You put them before the noun they describe and you’re done. In French however, the placement of adjectives varies. And if that wasn’t enough to confuse you and me, adjectives also change depending on whether the noun they describe is masculine, feminine, singular or plurial.
- French to english:ex-1
- Adjectives to the test.
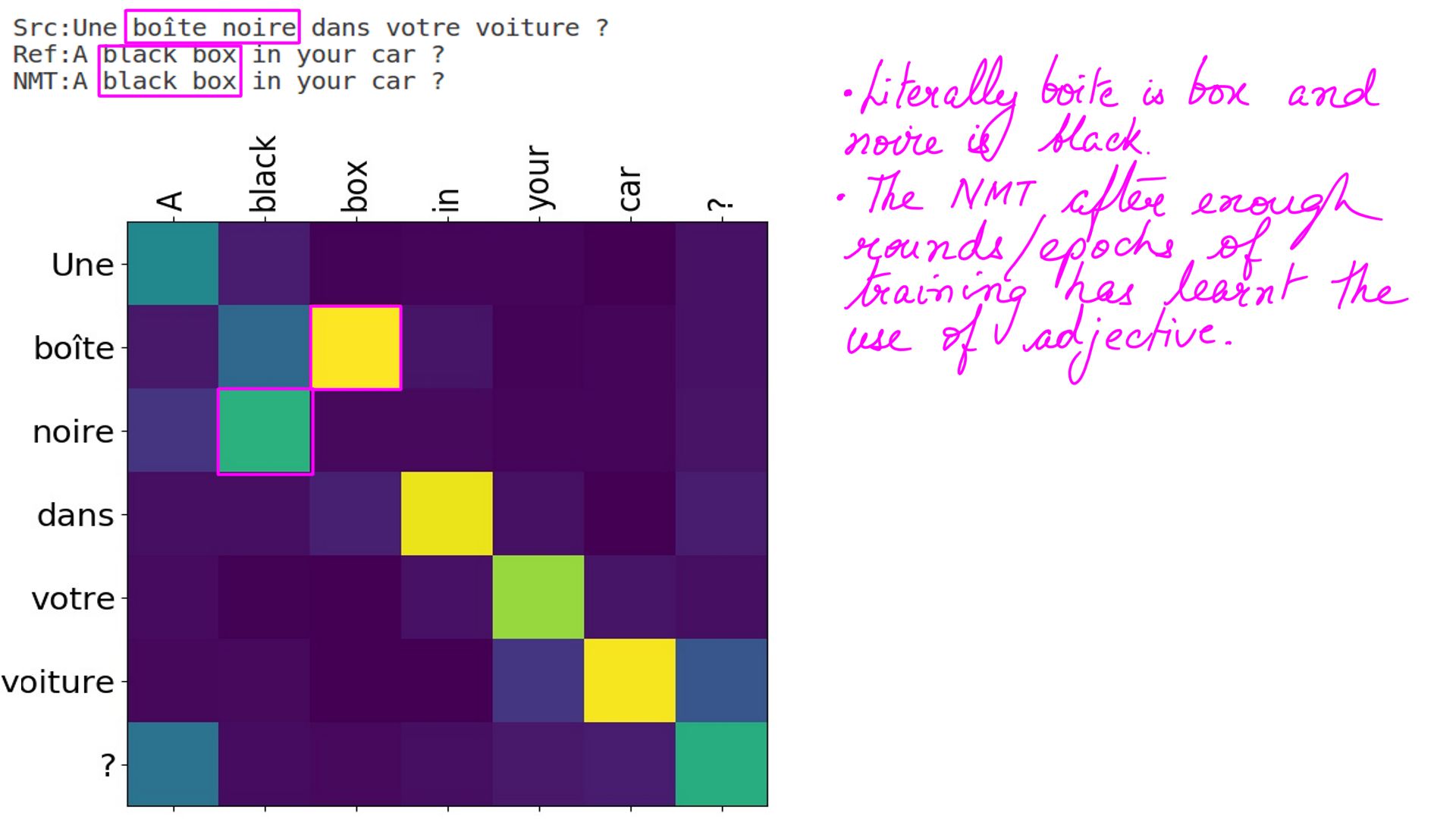
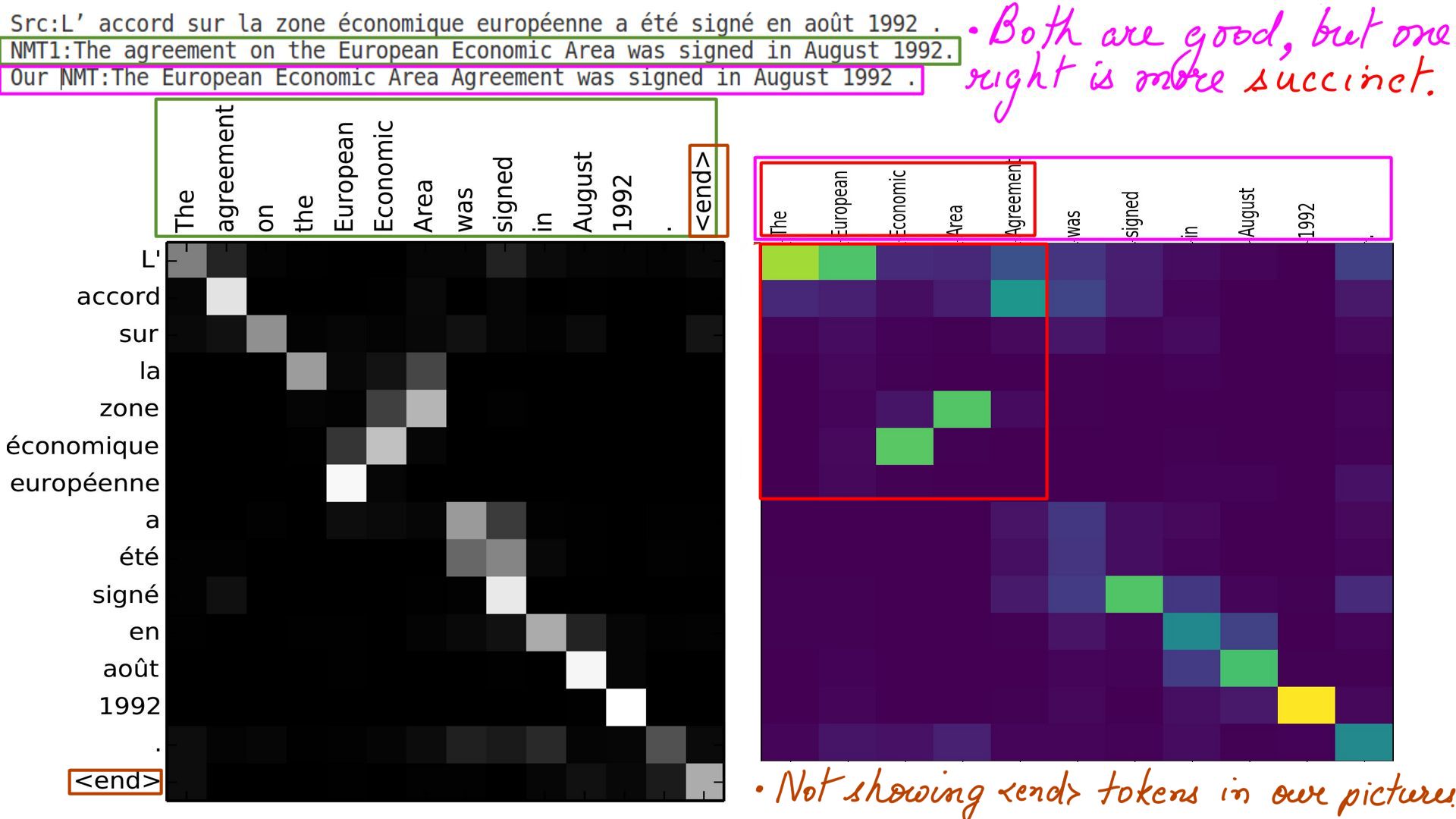
- French to english:ex-2
- I would like to argue that the one on the right is more finely tuned, because its translations are much more succinct.
Other Languages
What about supporting other Indian languages? Technically it is a no brainer. It will take half a day for my team to set it up. The only problem is data. We do not have high-quality data. Irony is I did not find high-quality data for Hindi-to-English training in India. For that, I have to thank Charles University, Czech Republic and Statistical Machine Translation for loaning it to me. If you find parallel corpus for the data of the language(s) you want to support ping us at support@stillwaters.ai. For Kannada I have facing extreme pressure from home as well as office for obvious reasons. ;-) Tamil, Telegu, Punjabi, Malyalam, Gujrati, Bengali, Japanese e.t.c. Imagine speaking to your machine in your native language. Even local dialects can be supported like Swiss-German, Bhojpuri etc.
Case Studies
Imagine this, if an AI model like NMT can excel at translation merely by looking at examples, what else can it be good at by the same analogy. But lets stay with translation for a while and imagine this. If the translations can be as good as you what you have seen, and can be bettered with better data, the NMT does this by storing in its “internal neural representation” the knowledge it has gained on the languages it has been trained on. Now imagine what one could achieve with the interface to a machine being a Natural Language. A general Listing would be too exhaustive, so down below are some of the applications that we have directly built using this technology and its derivatives in the last 3-4 years.
Natural Language Processing case studies
- Automating L1/L2/L3 support systems: Most organizations have historical data stored in sources(mails, JIRA, in house Knowledge bases, application logs and, source code). Most support systems manually feed of this data collectively referred to as sources. Automated Support System has the smarts to read or hear a support query and because it contexually understands the query(using the below mentioned technologies), transform it to form that can be fired against one or more of the above sources. The sources respond with the information which is then assimilated. The assimilated results are then transformed into Natural Language and sent back to the client.
* Speech to text: Converting speech to text.
* Text to speech: Converting text to speech.
* Handwriting recognition:
* Speech Translation: Speech from one language to another.
* SQL Query Generation: Given a query in Natural Language, the MODEL translates it to an SQL
query that is ready to be fired against a database or a knowledge base.
* Machine Comprehension: Given a passage of text, the MODEL can answer queries based on that.
(Recall middle school syllabus, Who said this to whom, only this time its the algorithm on the spot.)
* Parts of Speech taggings: Given a passage of text, the MODEL can mark the various parts of speech in
a sentence.
* Name Entity Recognition: Given a passage of text, the MODEL can mark the entities(Nouns) and their types.
* Sarcasm Detection:
* Word sense disambiguation:
* Hate speech Detection:
* Tone softening: Soften the tone of a sentence from being harsh and critical to a more polite tone without
making the intent of the message ambigous.
* Text Summarization: Given a passage, the model summarizes it.
* Topic Modelling: Given a passage, the MODEL suggests the topic for it.
Sequence based Case studies
Technologies like LSTM, Attention, Memory are fantastic at recognizing patterns in a sequence. Which is why they are great at speech, text etc. But language is not the only sequential data we deal with. Majority of dataset around us are some kind of sequence. Some examples are vehicle postions over time, stock prices, and all kinds of timeseies data. The details of these projects are extremely proprietary but the idea is simple. Presenting a few of them with a very short description. Neural Microprocessor Branch Predictions is something that we are extremely proud of. Once I finish the Natural Language Processing series, Ill look into the below mentioned case studies in a more detailed future post.
- Neural Microprocessor Branch Predictions: Depending on the exact CPU and code, Control-changing instructions, like branches in code add uncertainty in the execution of dependent instructions and lead to large performance loss in severely pipelined processors. Accurate prediction of branches is vital for modern CPUs. The latency incurred due to mispredictions is roughly proportionate to the size of the pipeline. For the last 4-5 generation CPUs (5-6 years) this should range between 12-30 cycles. It also wastes energy executing the wrong instruction path. Branch prediction improvements can boost performance and energy consumption significantly. For example, experiments on real processors showed that reducing the branch mispredictions by 3/4 improved the processor performance by 29%.
- Time Series Data: Return prediction on gold pricing is an example of time series data in finance. Traditionally forecasting time series data uses techniques like univariate Autoregressive (AR), univariateMoving Average (MA), Simple Exponential Smoothing (SES),and more notably Autoregressive Integrated Moving Average(ARIMA) with its many variations. However, with LSTMs when combined with Attention in some form, the improvement is upwards of 88%.
Summary
Is this the State-of-the-art(SOTA) technology for Artificial Intelligence in the field of Natural Language Processing? This field is a moving target and innovations are happening at a blinding speed. The scary part is this was SOTA less than a year ago. But today we have systems that take accuracy to a different level completely. Why then talk about NMTs? Well, NMTs are a major cog in the wheel for whatever is SOTA today. SOTA systems are called “Transformers” and they are an evolution over NMTs. So a great understanding of NMTs and its pieces is a precondition for understanding Transformers. In the immediate next post I’ll get under the skin of NMT and its back-propagation.